特征选择的目标
- 1.提高模型性能:去除无关特征或冗余特征,可以降低过拟合的风险,使模型更好地捕获数据中的真实模式。
- 2.降低计算成本:更少的特征意味着更快的训练速度和更少的内存占用。
- 3.增强模型可解释性:拥有较少特征的模型更容易理解和解释其决策过程。
- 4.缓解维度灾难:减少特征数量,缓解维度灾难,特别是在特征数量远大于样本数量时。
特征选择的常用方法
特征选择的方法通常分为三大类:过滤式、包裹式和嵌入式。
1.过滤式方法
过滤式方法独立于任何特定的学习算法,仅依靠特征自身的统计特性或特征与目标变量之间的关系来进行评估。
%matplotlib inline
%config InlineBackend.figure_format = "svg"
import pandas as pd
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams["font.sans-serif"]=['SimHei']
plt.rcParams['axes.unicode_minus']= False #解决负数无法显示
from tableone import TableOne
import statsmodels.api as sm
from statsmodels.imputation import mice
from scipy.stats import mannwhitneyu
from scipy import stats
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, Lasso
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.feature_selection import mutual_info_regression, SelectKBest, chi2, RFE
from sklearn.ensemble import RandomForestRegressor
# 加载加州房价数据集 (作为Boston数据集的替代)
# 加州房价数据集共有 8 个特征
housing = fetch_california_housing(as_frame=True)
X_df = housing.data
y_series = housing.target
feature_names = X_df.columns.tolist()
y_log = np.log1p(y_series)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_df, y_log, test_size=0.3, random_state=42)
# 特征缩放:对特征进行标准化,这对基于距离或梯度的模型(如线性回归和Lasso)至关重要
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
X_train_scaled_df = pd.DataFrame(X_train_scaled, columns=feature_names, index=X_train.index)
X_test_scaled_df = pd.DataFrame(X_test_scaled, columns=feature_names, index=X_test.index)
print(f"使用的特征数量: {len(feature_names)}")
print(f"训练集形状: X_train={X_train_scaled_df.shape}, y_train={y_train.shape}")
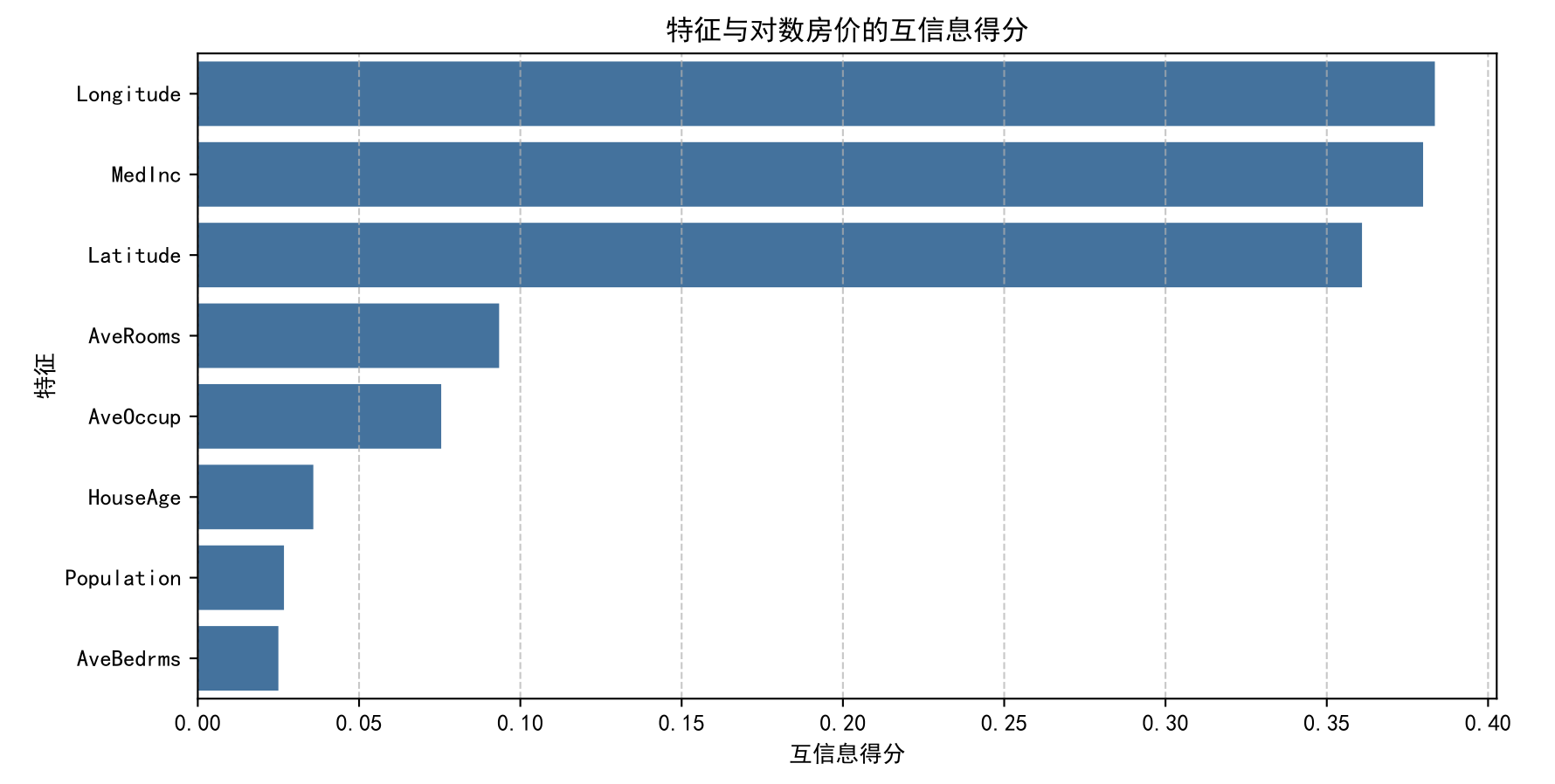
# 计算每个特征与目标变量的互信息 (回归任务)
mi_scores_reg = mutual_info_regression(X_train_scaled_df, y_train, random_state=42)
mi_scores_df_reg = pd.DataFrame({'Feature': feature_names, 'MI_Score': mi_scores_reg})
mi_scores_df_reg = mi_scores_df_reg.sort_values(by='MI_Score', ascending=False)
print("互信息得分 (Mutual Information Scores):\n", mi_scores_df_reg)
# 绘制互信息得分条形图
plt.figure(figsize=(10, 5))
sns.barplot(x='MI_Score', y='Feature', data=mi_scores_df_reg)
plt.title('特征与对数房价的互信息得分')
plt.xlabel('互信息得分')
plt.ylabel('特征')
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()
# 选择 Top 5 特征
top_n_mi_reg = 5
selected_features_mi_reg = mi_scores_df_reg['Feature'].head(top_n_mi_reg).tolist()
print(f"\n基于互信息选择的Top {top_n_mi_reg}个特征: {selected_features_mi_reg}")
# 使用选定特征训练模型并评估
model_mi_reg = LinearRegression()
model_mi_reg.fit(X_train_scaled_df[selected_features_mi_reg], y_train)
y_pred_mi_reg = model_mi_reg.predict(X_test_scaled_df[selected_features_mi_reg])
mse_mi_reg = mean_squared_error(y_test, y_pred_mi_reg)
print(f"使用互信息选择特征后的模型均方误差 (MSE): {mse_mi_reg:.4f}")
使用互信息选择特征后的模型均方误差 (MSE): 0.0490
2.包裹式方法
包裹式方法将特征选择视为一个搜索问题。它使用一个特定的学习算法(如逻辑回归、SVM)作为评估器,来评估特征子集的质量。
它通过不断地尝试不同的特征子集,并用目标模型进行训练和验证,根据模型的性能指标(如准确率、F1分数等)来选择最佳子集。
# 使用线性回归作为基估计器
estimator_rfe = LinearRegression()
# RFE将递归地消除特征,直到剩余指定数量的特征
# 我们选择保留 5 个特征
n_features_to_select = 5
selector_rfe_reg = RFE(estimator=estimator_rfe, n_features_to_select=n_features_to_select, step=1)
selector_rfe_reg.fit(X_train_scaled_df, y_train)
# 获取特征排名 (1表示选中)
rfe_ranking_reg = pd.DataFrame({'Feature': feature_names, 'Ranking': selector_rfe_reg.ranking_})
rfe_ranking_reg = rfe_ranking_reg.sort_values(by='Ranking', ascending=True)
print("\nRFE特征排名 (Ranking 1 means selected, higher means less important):\n", rfe_ranking_reg)
# 绘制特征排名条形图
plt.figure(figsize=(10, 5))
sns.barplot(x='Ranking', y='Feature', data=rfe_ranking_reg)
plt.title(f'RFE特征排名 (目标特征数量: {n_features_to_select})')
plt.xlabel('排名 (1代表被选中)')
plt.ylabel('特征')
plt.gca().invert_yaxis()
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()
# 获取选择的特征名称
selected_features_rfe_reg = X_train_scaled_df.columns[selector_rfe_reg.get_support()].tolist()
print(f"\n基于RFE选择的Top {len(selected_features_rfe_reg)}个特征: {selected_features_rfe_reg}")
# 使用选定特征训练模型并评估
model_rfe_reg = LinearRegression()
model_rfe_reg.fit(X_train_scaled_df[selected_features_rfe_reg], y_train)
y_pred_rfe_reg = model_rfe_reg.predict(X_test_scaled_df[selected_features_rfe_reg])
mse_rfe_reg = mean_squared_error(y_test, y_pred_rfe_reg)
print(f"使用RFE选择特征后的模型均方误差 (MSE): {mse_rfe_reg:.4f}")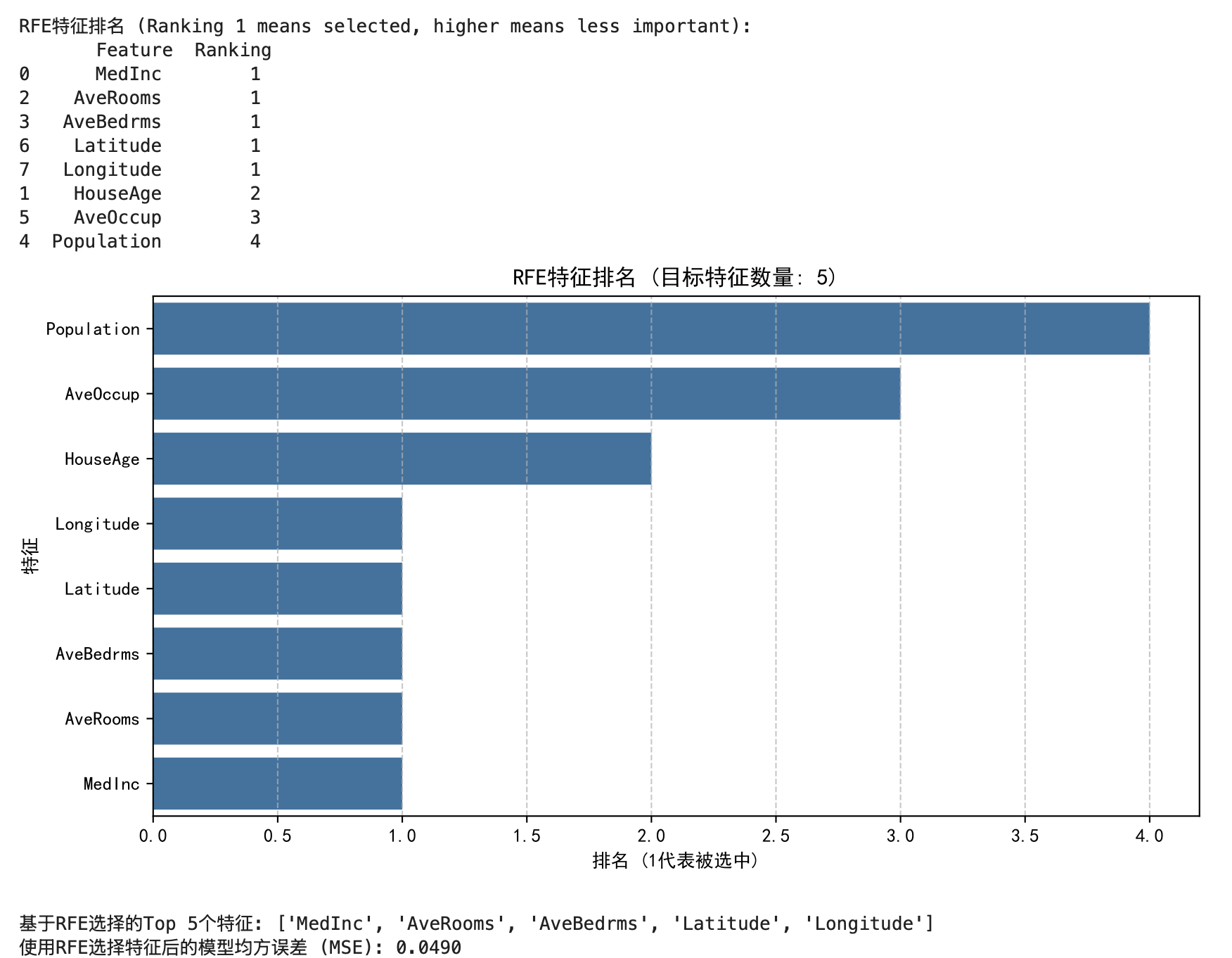
3.嵌入式方法
嵌入式方法将特征选择过程与模型训练过程融合在一起。模型在训练过程中自行选择最重要的特征。
# C值较小 (alpha 较大) 会导致正则化强度高,更多系数被压缩为零
# 在sklearn中,alpha = 1/C
lasso_reg = Lasso(alpha=0.01, random_state=42)
lasso_reg.fit(X_train_scaled_df, y_train)
# 获取特征系数
lasso_coefficients_df = pd.DataFrame({'Feature': feature_names, 'Coefficient': lasso_reg.coef_})
lasso_coefficients_df['Abs_Coefficient'] = np.abs(lasso_coefficients_df['Coefficient'])
lasso_coefficients_df = lasso_coefficients_df.sort_values(by='Abs_Coefficient', ascending=False)
print("\nLasso 回归特征系数 (绝对值降序):\n", lasso_coefficients_df)
# 绘制特征系数条形图
plt.figure(figsize=(10, 5))
sns.barplot(x='Coefficient', y='Feature', data=lasso_coefficients_df)
plt.title(f'Lasso 回归特征系数 (alpha={lasso_reg.alpha})')
plt.xlabel('特征系数')
plt.ylabel('特征')
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.axvline(x=0, color='red', linestyle='--', alpha=0.8)
plt.show()
# 选择系数不为零的特征
# 设置一个小的阈值(如 1e-4)来判断系数是否为零
threshold = 1e-4
selected_features_lasso_reg = lasso_coefficients_df[lasso_coefficients_df['Abs_Coefficient'] > threshold]['Feature'].tolist()
print(f"\n基于Lasso选择的特征 (系数 > {threshold}): {selected_features_lasso_reg}")
print(f"Lasso选择的特征数量: {len(selected_features_lasso_reg)}")
# 使用选定特征训练模型并评估
model_lasso_select = LinearRegression()
model_lasso_select.fit(X_train_scaled_df[selected_features_lasso_reg], y_train)
y_pred_lasso_select = model_lasso_select.predict(X_test_scaled_df[selected_features_lasso_reg])
mse_lasso_select = mean_squared_error(y_test, y_pred_lasso_select)
print(f"使用Lasso选择特征后的模型均方误差 (MSE): {mse_lasso_select:.4f}")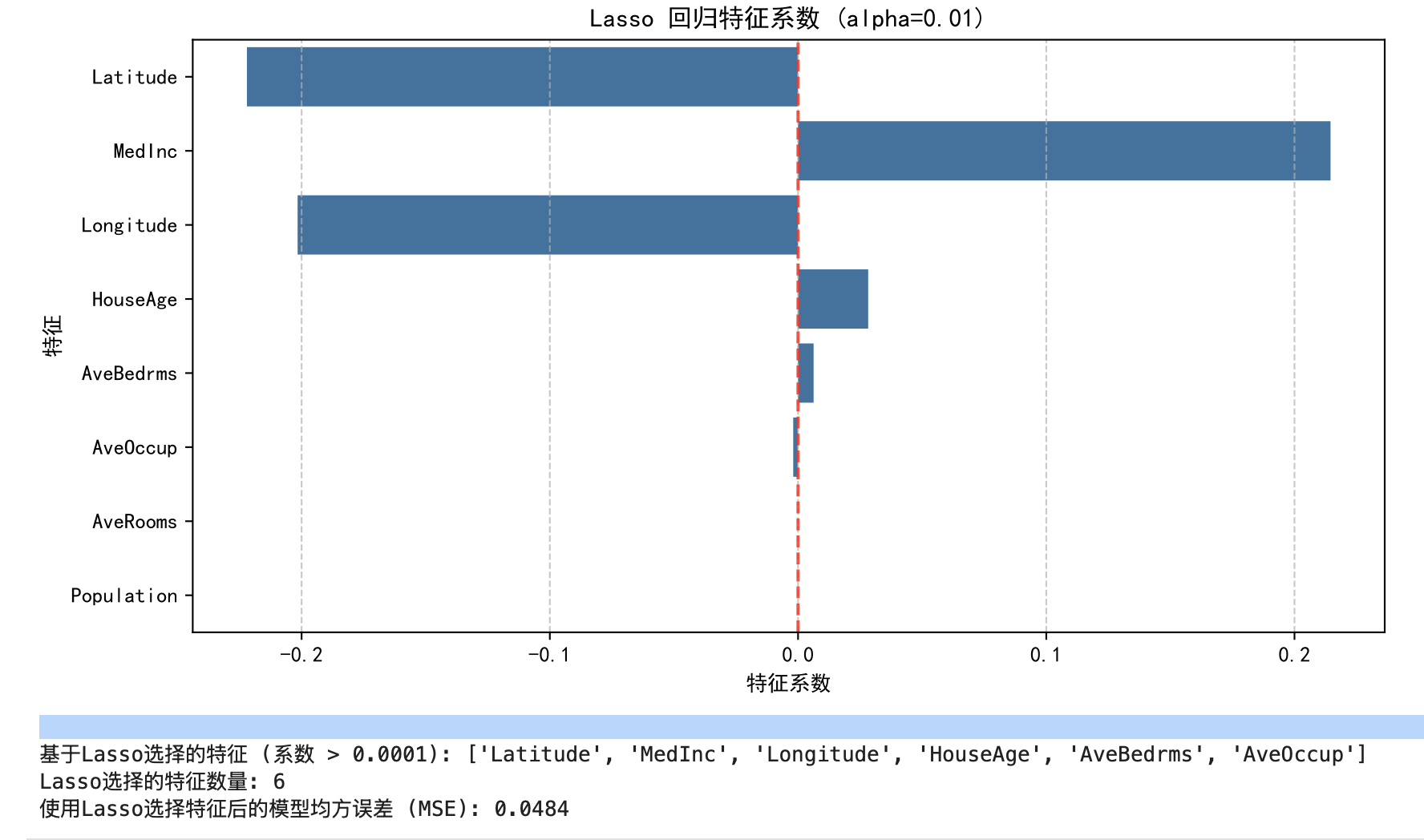
特别申明:本文为转载文章,转载自程序员学长,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/FZiW39Z_YvINS_bjQR5fhA
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫