1. 设置工作路径
- 使用
setwd("/Users/xujun/Downloads/R\ work")指定当前工作目录为/Users/xujun/Downloads/R\ work。
2. 安装和加载 jskm 包
- 使用
devtools包从 GitHub 安装jskm包,并将其加载到当前 R 会话中。
3. 加载生存分析数据集
- 加载
survival包中的colon数据集,并查看其变量名及其含义,如患者的年龄、治疗方案、事件状态等。
4. 生存曲线拟合与绘图
- 使用
survfit()函数根据治疗方案(rx)拟合生存曲线,并使用jskm()函数绘制生存曲线图。 - 绘图中包括多个参数配置,如显示风险人数表、p 值、坐标轴标签等。
5. 累积发生率分析
- 计算并绘制累积发生率(1 – 生存概率),展示不同时间点的累积风险。
6. 里程碑分析
- 进行生存数据的里程碑分析,通过指定时间点(500天)来观察生存率。
7. 竞争风险分析
- 创建一个新的状态变量(
status2),表示竞争风险,基于此变量重新拟合生存曲线并绘制图形。
8. 主题设置和样式调整
- 使用
jskm()函数绘制图形,应用不同的主题样式(如 “jama” 和 “nejm”),并自定义图形的视觉效果。
9. 加权 Kaplan-Meier 图
- 加载
survey包,使用pbc数据集进行加权 Kaplan-Meier 曲线分析。 - 通过广义线性模型预测随机化的概率,并根据随机化的结果计算并绘制生存曲线。
#### 0.设置工作路径
setwd("/Users/xujun/Downloads/R\ work")
#### 1.从github安装jskm包
# install.packages("devtools")
library(devtools)
# install_github("jinseob2kim/jskm")
library(jskm)
# 作者:Jinseob Kim
# 示例
# 生存概率
# 加载数据集
library(survival)
colon
data(cancer, package="survival")
# 忽略这个警告
#> Warning in data(colon): data set 'colon' not found
?colon
names(colon)
# id: 病例编号
# study: 所有患者的值都为1
## rx: 治疗方案 - Obs(观察)、Lev(左旋咪唑)、Lev(左旋咪唑)+5-FU
## sex: 性别 - 1=男性
# age: 年龄(岁)
## obstruct: 肿瘤是否导致结肠梗阻
## perfor: 结肠是否穿孔
## adhere: 是否与附近器官粘连
# nodes: 检测到癌症的淋巴结数量
# time: 事件发生或审查的天数
# status: 审查状态
## differ: 肿瘤分化程度(1=高分化,2=中等分化,3=低分化)
## extent: 局部扩散程度(1=粘膜下层,2=肌层,3=浆膜层,4=邻近结构)
## surg: 从手术到注册的时间(0=短,1=长)
# node4: 是否有超过4个阳性淋巴结
## etype: 事件类型:1=复发,2=死亡
# 使用survfit函数拟合生存曲线,基于治疗方案(rx)进行分组
# Surv(time, status) 创建生存对象,其中time是生存时间,status是审查状态
fit <- survfit(Surv(time, status) ~ rx, data = colon)
# 绘制生存曲线图
jskm(fit)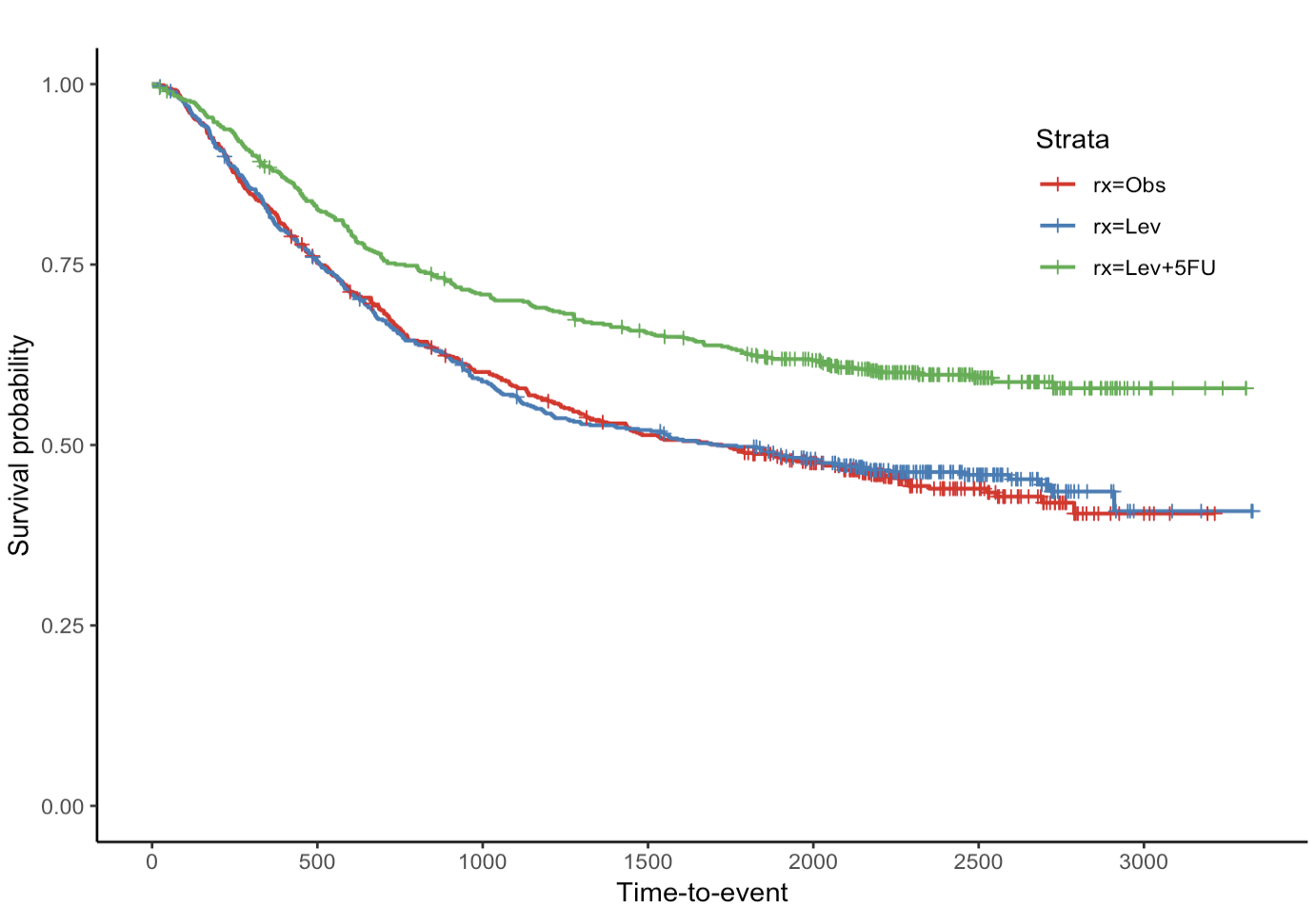
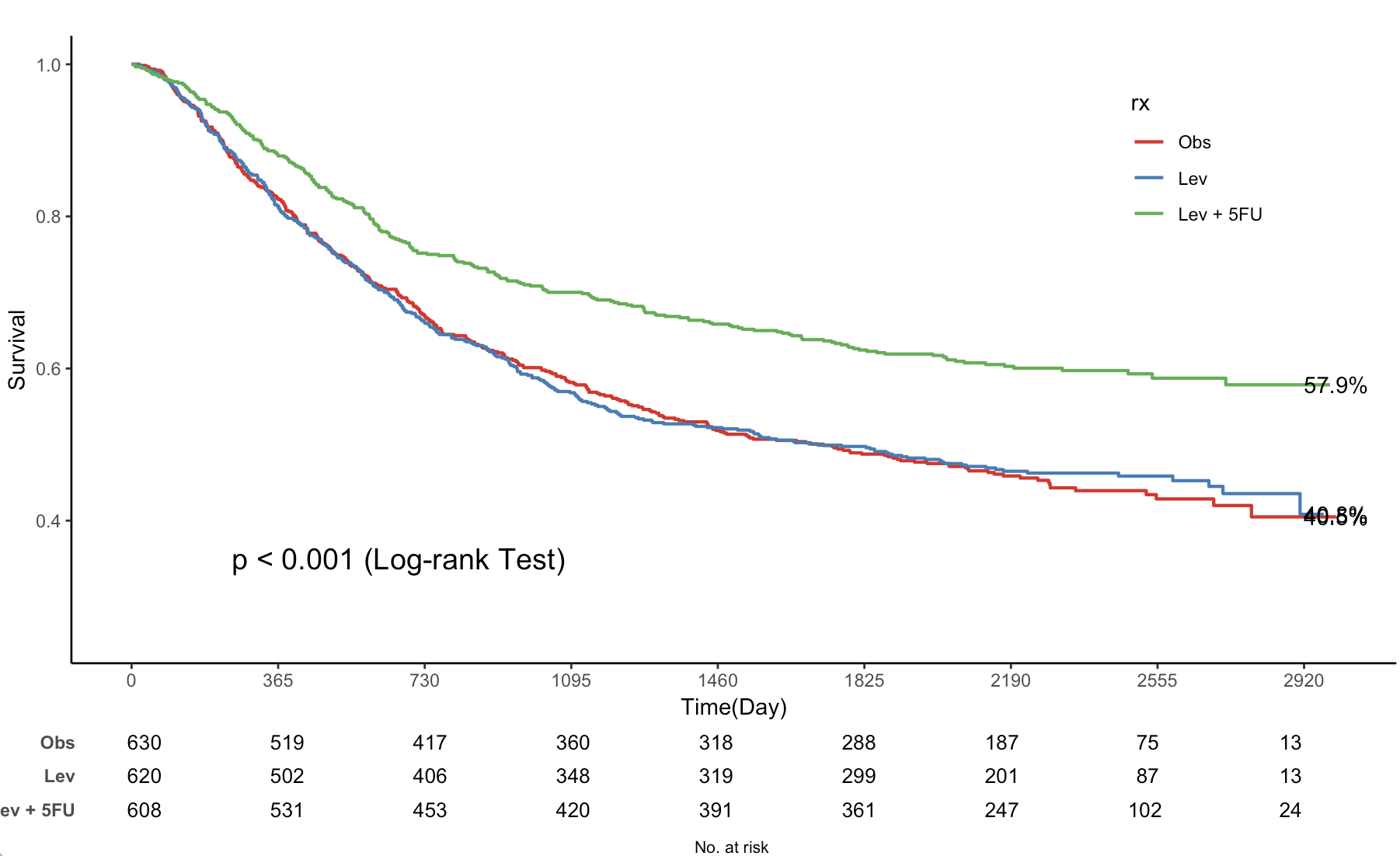
jskm(fit,
table = T, # 显示生存曲线下方的风险人数表
pval = T, # 显示p值
label.nrisk = "No. at risk", # 风险人数表的标签
size.label.nrisk = 8, # 风险人数表标签的字体大小
xlabs = "Time(Day)", # x轴标签,表示时间(天)
ylabs = "Survival", # y轴标签,表示生存概率
ystratalabs = c("Obs", "Lev", "Lev + 5FU"), # 生存曲线图例标签
ystrataname = "rx", # 分组变量的名称
marks = F, # 是否在生存曲线上标记审查点,F表示不标记
timeby = 365, # x轴时间间隔(单位:天)
xlims = c(0, 3000), # x轴范围(0到3000天)
ylims = c(0.25, 1), # y轴范围(0.25到1)
showpercent = T # 在y轴显示百分比形式的生存概率
)
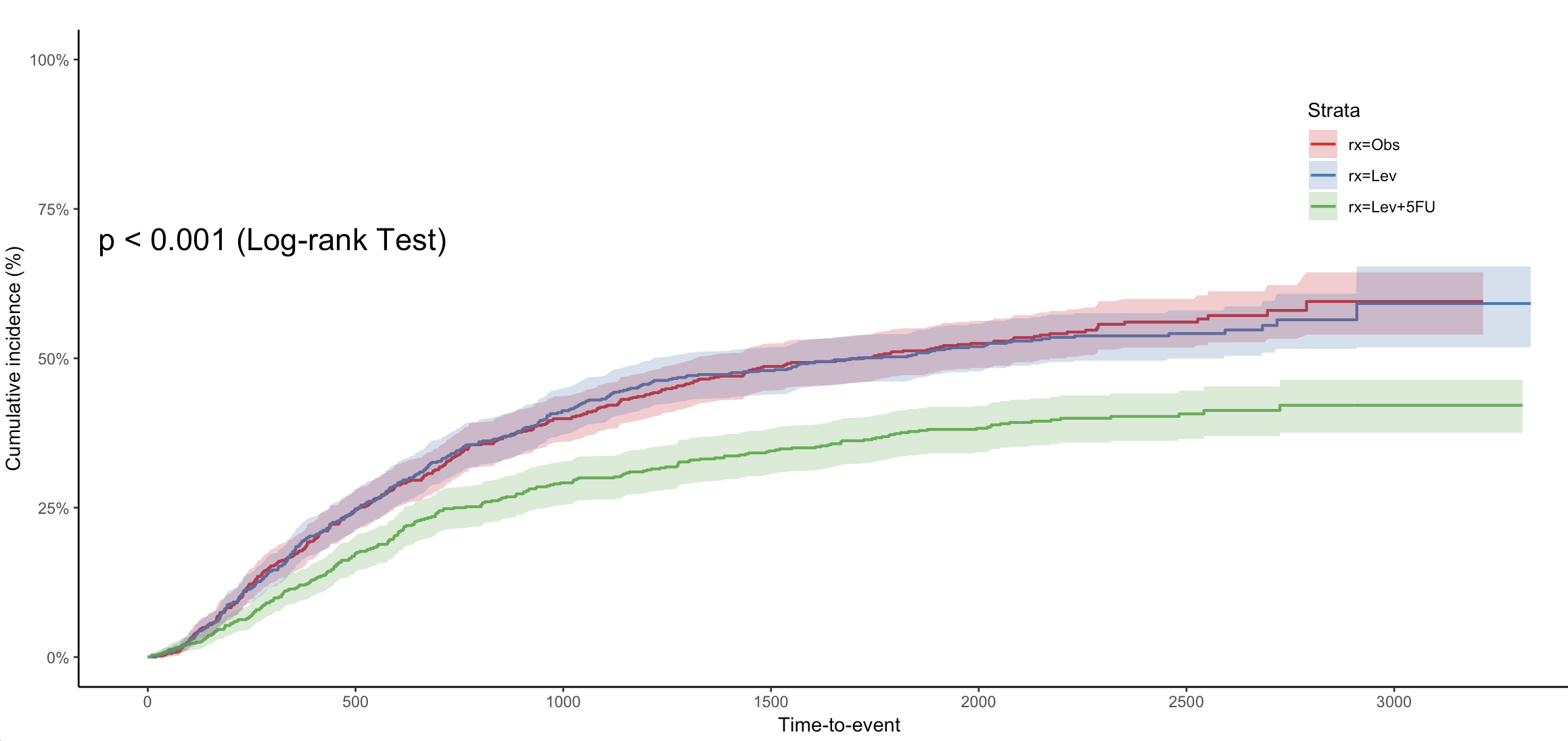
# 累积发生率:1 - 生存概率
jskm(fit,
ci = T, # 显示置信区间
cumhaz = T, # 显示累积风险曲线
mark = F, # 是否在曲线上标记审查点,F表示不标记
ylab = "Cumulative incidence (%)", # y轴标签,表示累积发生率(百分比)
surv.scale = "percent", # 将生存概率的比例转换为百分比形式
pval = T, # 显示p值
pval.size = 6, # p值字体大小
pval.coord = c(300, 0.7) # p值的位置坐标(x=300, y=0.7)
)
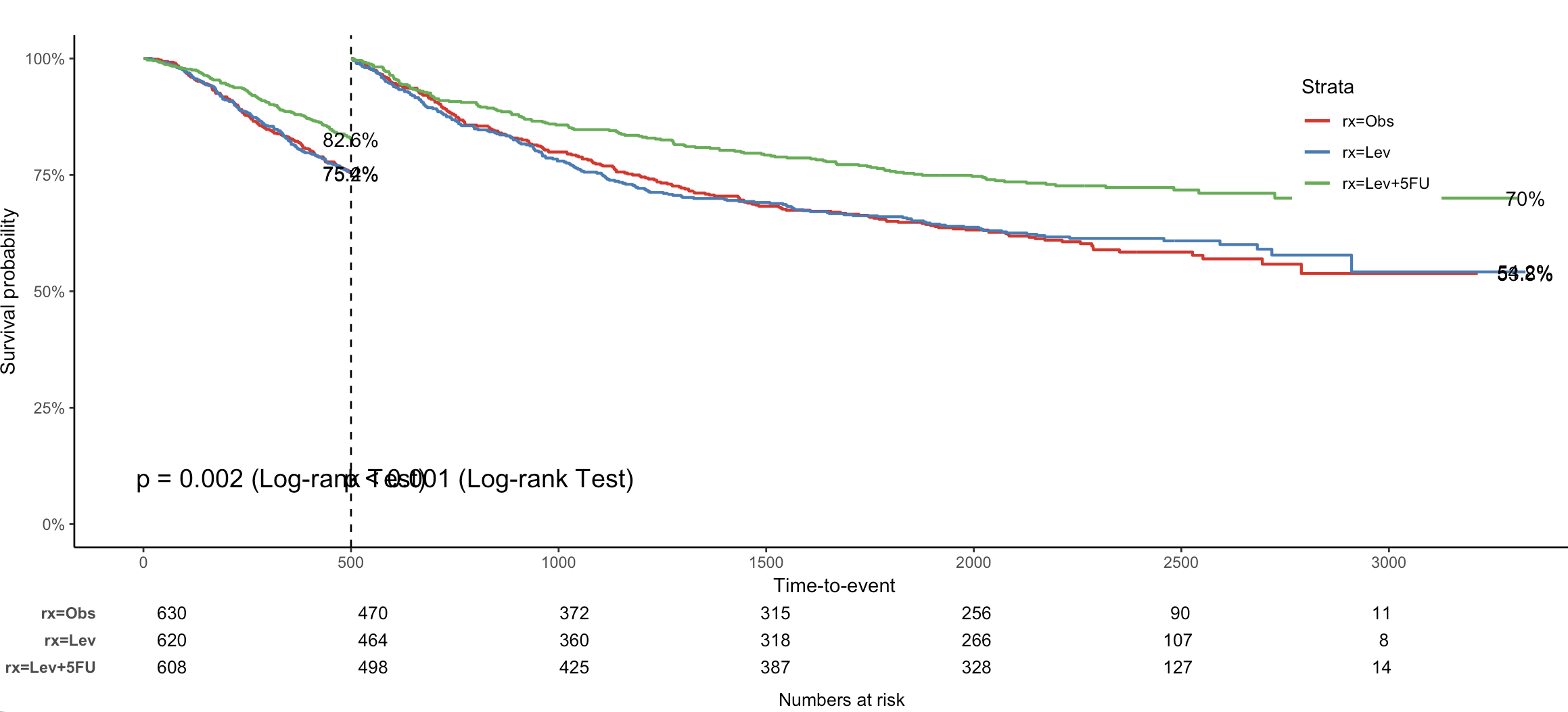
# Landmark analysis
# 里程碑分析/时间点分析
jskm(fit,
mark = F, # 是否在生存曲线上标记审查点,F表示不标记
surv.scale = "percent", # 将生存概率的比例转换为百分比形式
pval = T, # 显示p值
table = T, # 显示生存曲线下方的风险人数表
cut.landmark = 500, # 里程碑时间点,单位为天(500天)
showpercent = T # 在y轴显示百分比形式的生存概率
)
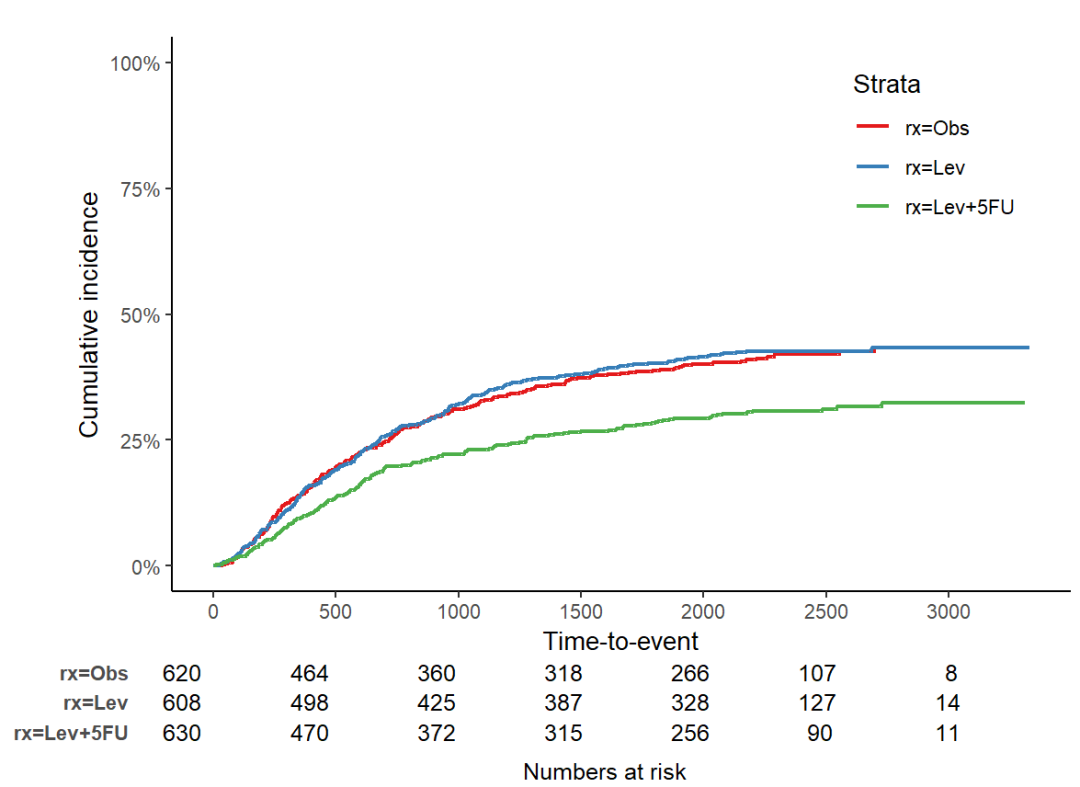
# Competing risk analysis
# status2 variable: 0 - censoring, 1 - event, 2 - competing risk
## Make competing risk variable, Not real
#### 竞争风险分析
# status2 变量: 0 - 删失,1 - 事件,2 - 竞争风险
## 创建竞争风险变量,注意这不是实际数据
View(colon) # 查看 colon 数据集
colon$status2 <- colon$status # 创建新的 status2 变量,并将其初始值设为 status 变量的值
colon$status2[1:400] <- 2 # 将前400个数据的 status2 值设为2,表示竞争风险
colon$status2 <- factor(colon$status2) # 将 status2 转换为因子类型
View(colon) # 再次查看 colon 数据集,以确认更改
# 使用 survfit 函数拟合生存曲线,基于治疗方案(rx)和新的 status2 变量进行分组
fit2 <- survfit(Surv(time, status2) ~ rx,
data = colon)
# 绘制生存曲线,适用于竞争风险分析
jskm(fit2,
mark = F, # 是否在生存曲线上标记审查点,F表示不标记
surv.scale = "percent", # 将生存概率的比例转换为百分比形式
table = T, # 显示生存曲线下方的风险人数表
status.cmprsk = "1" # 指定竞争风险状态为"1"
)
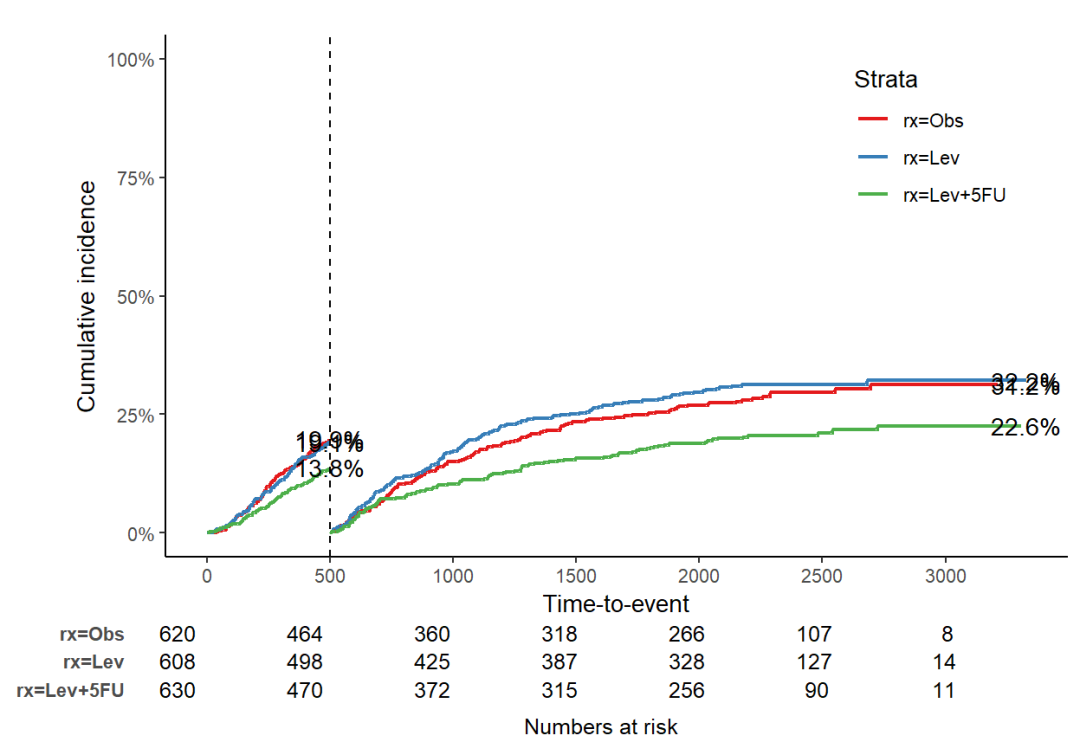
jskm(fit2,
mark = F, # 是否在生存曲线上标记审查点,F表示不标记
surv.scale = "percent", # 将生存概率的比例转换为百分比形式
table = T, # 显示生存曲线下方的风险人数表
status.cmprsk = "1", # 指定竞争风险状态为 "1"
showpercent = T, # 在 y 轴显示百分比形式的生存概率
cut.landmark = 500 # 里程碑时间点,单位为天(500天)
)
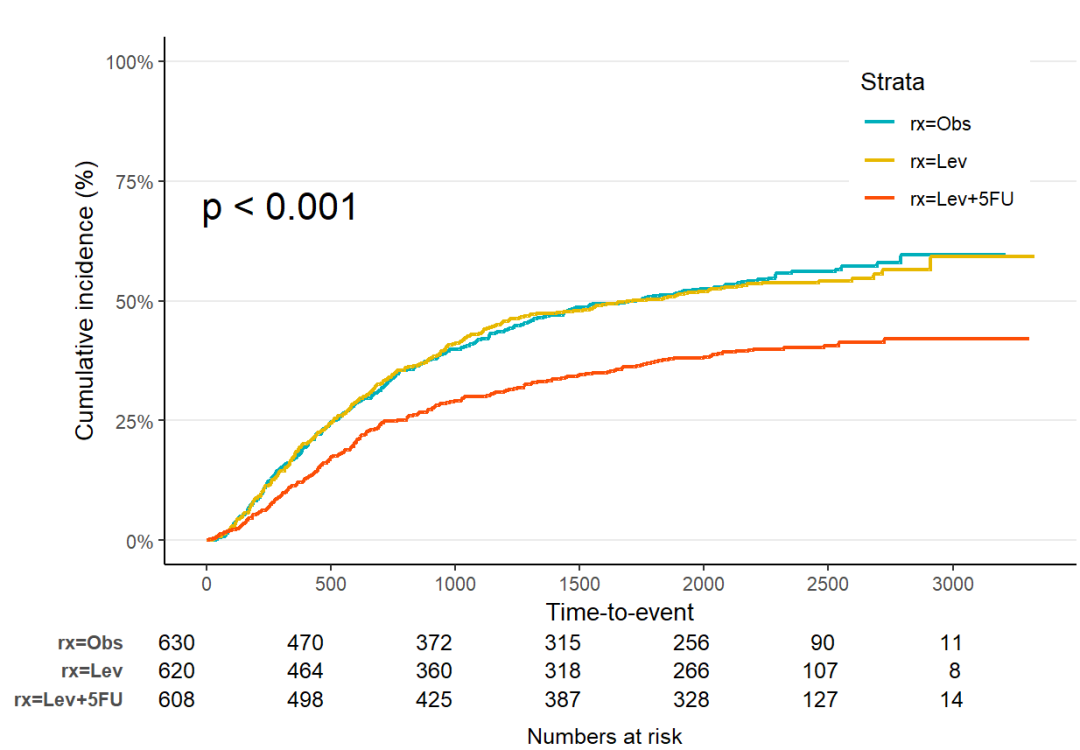
# 主题:Jama
jskm(fit,
theme = "jama", # 设置主题为 Jama
cumhaz = T, # 显示累积风险曲线
table = T, # 显示生存曲线下方的风险人数表
mark = F, # 是否在生存曲线上标记审查点,F表示不标记
ylab = "Cumulative incidence (%)", # y轴标签,表示累积发生率(百分比)
surv.scale = "percent", # 将生存概率的比例转换为百分比形式
pval = T, # 显示p值
pval.size = 6, # p值字体大小
pval.coord = c(300, 0.7) # p值的位置坐标(x=300, y=0.7)
)
转至:https://mp.weixin.qq.com/s/Gbv-Ahv4mBCm2kb7d4mt2A
特别申明:本文为转载文章,转载自左手python右手R,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/Gbv-Ahv4mBCm2kb7d4mt2A
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫