1、读取数据并查看shape及列索引
import numpy as np
import pandas as pd
df = pd.read_csv("./demo.csv")
print(df.shape)
print(df.columns)
2、删除某几列
df.drop(['Age', 'Height'], axis=1, inplace=True) #axis参数设置为 1 以放置列,0 设置为行。inplace=True参数设置为 True 以保存更改
print(df.shape)
print(df.columns)
3、读取部分列数据,可以使用 usecols 参数
df_spec = pd.read_csv("./demo.csv", usecols=['Height', 'Age', 'LOS'])
print(df_spec.head())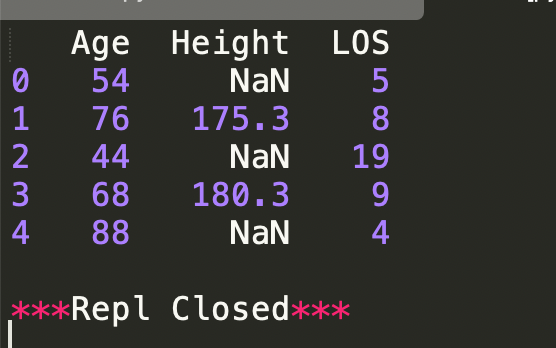
4、nrows,创建了一个包含 csv 文件前 400行的数据帧。还可以使用 skiprows 参数从文件末尾选择行。Skiprows=400 表示我们将在读取 csv 文件时跳过前 400 行。
df_partial = pd.read_csv("./demo.csv", nrows=400)
print(df_partial.shape)
df_partial_1 = pd.read_csv("./demo.csv", skiprows=400)
print(df_partial_1.shape)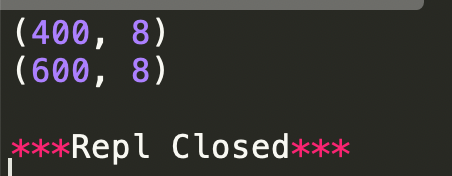
5、需要一个小样本来测试数据,使用 n 或 frac 参数来确定样本大小。
df= pd.read_csv("./demo.csv")
df_sample = df.sample(n=50)# 随机样本
df_sample2 = df.sample(frac=0.1)
print(df_sample)
print(df_sample2)6、检查缺失值。isna 函数确定数据帧中缺失的值。通过将 isna 与 sum 函数一起使用,我们可以看到每列中缺失值的数量。
print(df.isna().sum())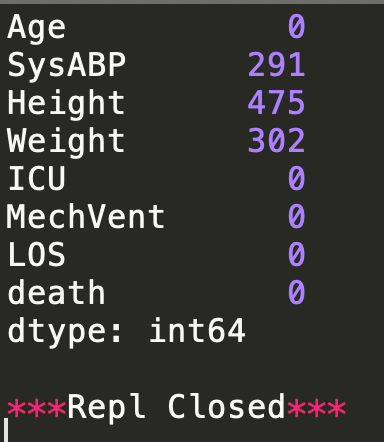
7、填充缺失值。也可根据列中的上一个或下一个值(例如方法=”ffill”)填充缺失值。
avg = df['Weight'].mean()
df['Weight'].fillna(value=avg, inplace=True)
print(df)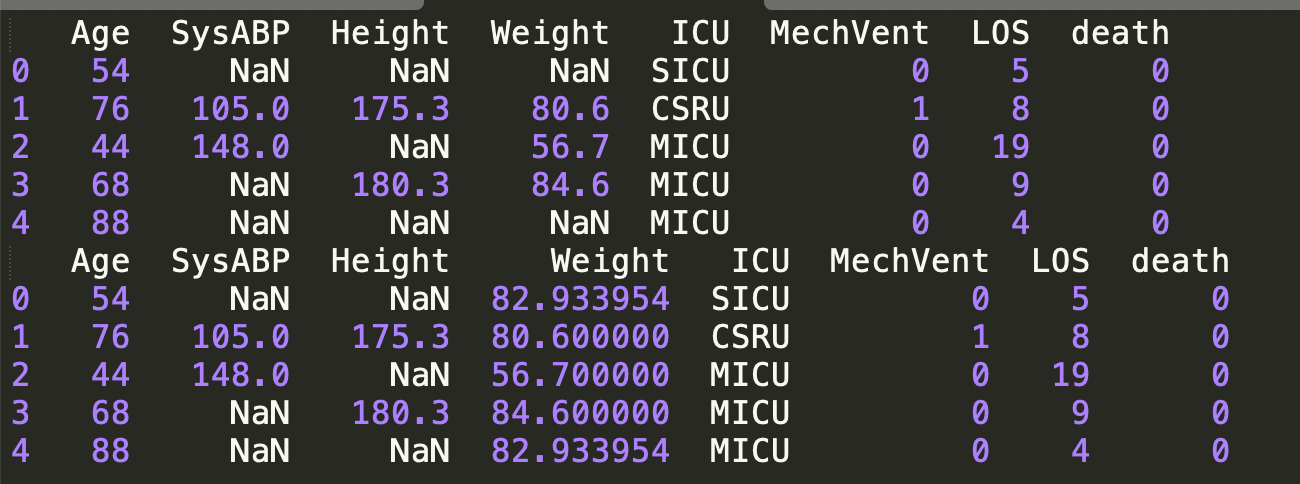
8、删除缺失值
df= pd.read_csv("./demo.csv")
print(df.isna().sum())
df.dropna(axis=0, how='any', inplace=True)
df1 = df
print(df1.isna().sum())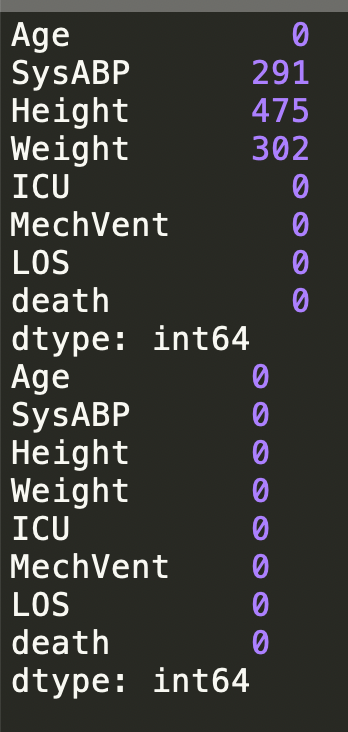
9、根据条件选择行
df= pd.read_csv("./demo.csv")
df1 = df[(df.ICU == 'MICU') & (df.Age == 63)]
print(df1.value_counts())
10、用查询描述条件
df= pd.read_csv("./demo.csv")
df2 = df.query('40 < Age < 100')
# 让我们通过绘制平衡列的直方图来确认结果。
df2['Age'].plot(kind='hist', figsize=(8,5))11、用 isin 描述条件
print(df[df['Age'].isin([19,20,21])])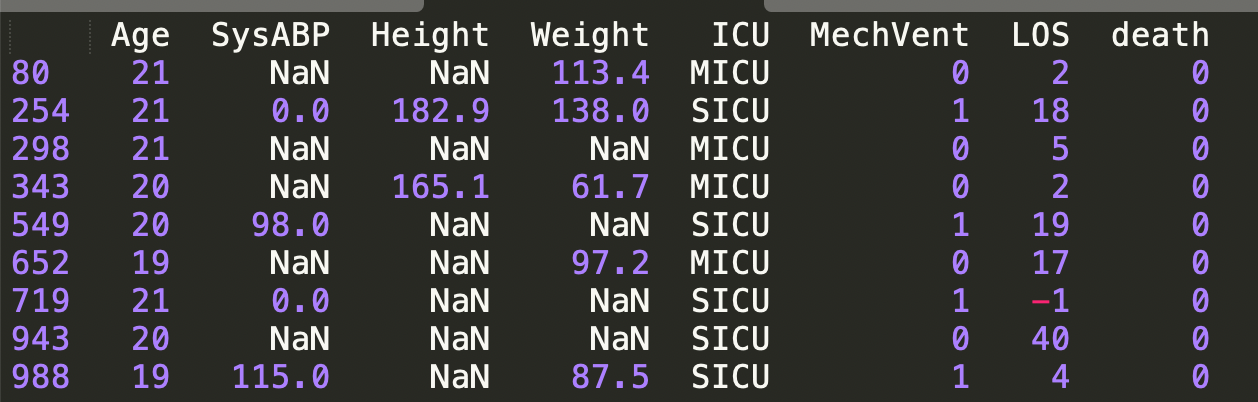
12、Groupby 函数
df1 = df[['Age','ICU','MechVent']].groupby(['ICU','MechVent']).mean()
print(df1)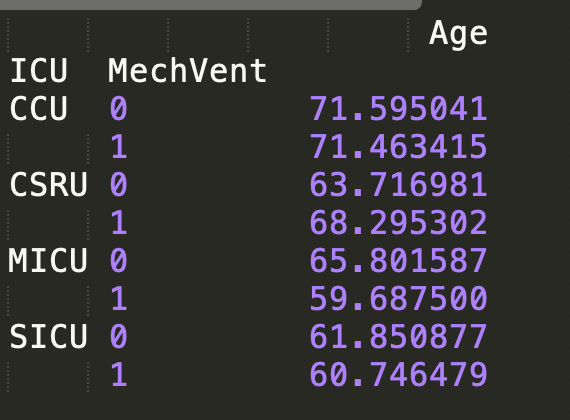
13、Groupby与聚合函数结合
df1 = df[['Age','ICU','MechVent']].groupby(['ICU','MechVent']).agg(['mean','count'])
df1.rename(columns={'Age':' patients age'},inplace=True) #可重命名
print(df1)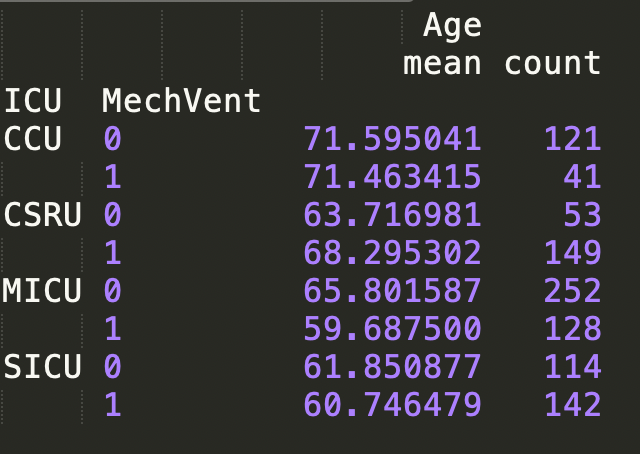
14、重置索引
print(df.reset_index())15、重置并删除原索引
df[['Age','ICU','MechVent']].sample(n=6).reset_index(drop=True)16、将特定列设置为索引set_index
df_new.set_index('Geography')17、插入新列
group = np.random.randint(10, size=6)
df_new['Group'] = group18、where 函数。它用于根据条件替换行或列中的值。默认替换值为 NaN,但我们也可以指定要作为替换值。
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)19、等级函数。等级函数为值分配一个排名。让我们创建一个列
df= pd.read_csv("./demo.csv")
df['rank'] = df['Age'].rank(method='first', ascending=False).astype('int')
print(df)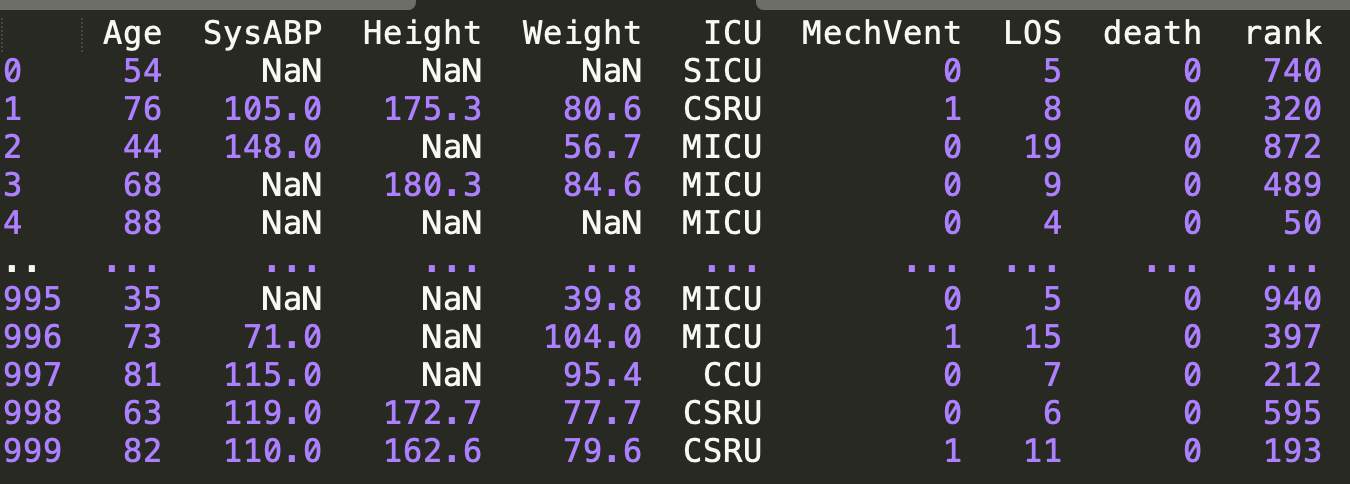
20、设置数据帧样式
df_new.style.highlight_max(axis=0, color='darkgreen')上述代码来源于:https://mp.weixin.qq.com/s/_3nI1uYO1Eap2X4QPBAlS
特别申明:本文为转载文章,转载自 Python学习与数据挖掘,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/_3nI1uYO1Eap2X4QPBAlSg
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫