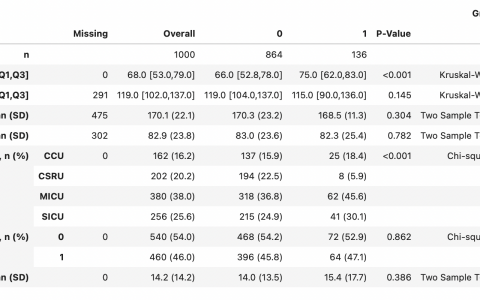
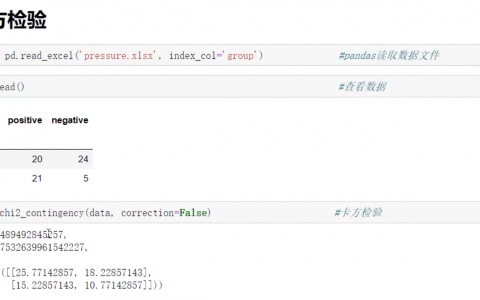
数据缺失绝对是统计分析中最为常见的问题之一,最常见的做法莫过于直接把数据导入软件进行分析,可是大多数统计模型会直接忽略有缺失值的记录,相当于在分析前先行对缺失值进行列表删除。当缺失值比较多的时候,这种做法会丢失大量的信息,如果缺失是非完全随机的,还有可能带来错误的结论。
数据缺失机制:完全随机缺失(Missing Completely At Random,MCAR)、随机缺失(Missing At Random,MAR)、非随机缺失(Missing At Non-Random,MANR)。MCAR是指数据的缺失是完全随机的,和变量自身或者其他变量的取值无关,实际中极为少见。MAR是指缺失值的丢失与本变量无关,而与数据集中其他(部分)变量有关。MANR是指数据的缺失不仅与其他变量的取值有关,也和自身取值有关。缺失值的处理方法:(1)删除;(2)单独成组分析;(3)填充。
缺失值填充的方法有很多,简单如直接用均值、众数进行填充,稍微复杂一些的如回归填充、最大期望(Expectation-Maximization,EM)、多重插补(Multiple Imputation,MI)等。
最大期望
多重插补
原创文章(本站视频密码:66668888),作者:xujunzju,如若转载,请注明出处:https://zyicu.cn/?p=11921
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫