分段回归(piecewise regression),顾名思义,回归式是“分段”拟合的。其灵活用于响应变量随自变量值的改变而存在多种响应状态的情况,二者间难以通过一种回归模型预测或解释时,不妨根据响应状态找到合适的断点位置,然后将自变量划分为有限的区间,并在不同区间内分别构建回归描述二者关系。分段回归最简单最常见的类型就是分段线性回归(piecewise linear regression),即各分段内的局部回归均为线性回归。
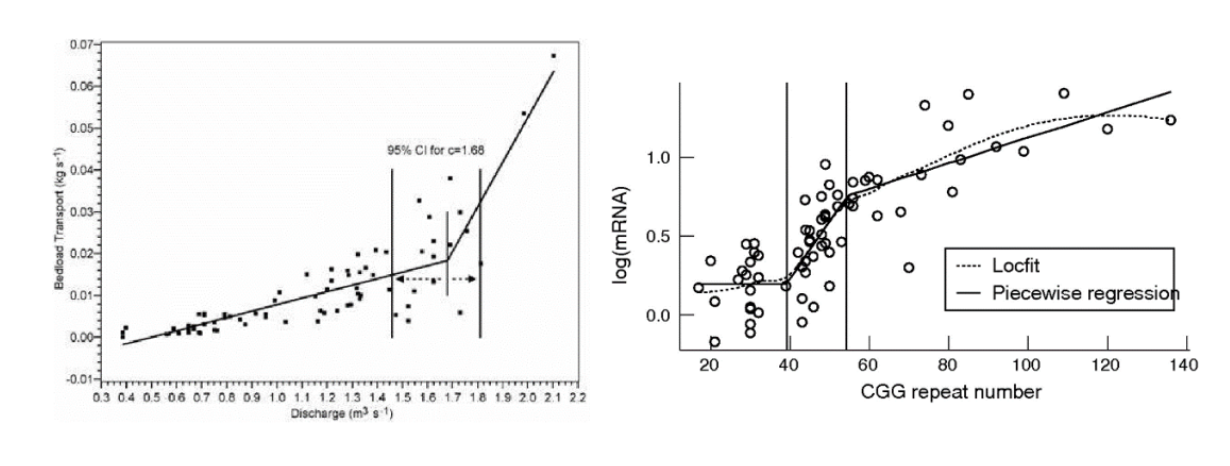
简单分段线性回归:以只有一个断点的一元分段线性回归为例,断点两侧描述为不同的一元线性回归式,并在断点处将两条回归线连接构成一个整体连续的响应模型。例如下式展示了某种简单样式:
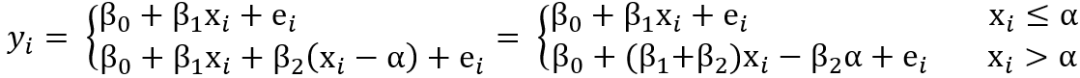
式中x为自变量,y为响应变量,α是断点(阈值),ei是独立的、平均误差为零、方差恒定、有限绝对矩的相加误差。xi是第i个自变量的值,当xi≤α,即自变量未超过断点阈值时,通过线性回归式β0+βixi+ei计算响应变量的估计值yi;当xi>α,即自变量越过断点阈值时,通过线性回归式β0+βixi+β2(xi-α)+ei计算响应变量的估计值yi。断点α两侧的两个线性回归的回归系数(斜率)分别为β1和β1+β2,β2可以解释为两个线性回归在斜率的差异。
由于两个线性回归之间存在断点,使得整体分段回归的一阶导数不连续,可能在很多常用的数值优化程序中出问题。为了避免这个问题,通常会在断点阈值α处添加一小段平滑曲线等使两个线性回归的拟合线在x=α处相交,即让它们在断点处具有强制的连续性,保证整体分段回归的一阶导数连续。
注意的是,尽管其称为分段线性回归,各分段内的局部回归均由线性回归式构成,但由于断点两侧描述了不同形式的变量响应,因此分段回归整体上体现了非线性的响应模式。
举例:示例数据“Arkansas.csv”
录了美国科罗拉多州阿肯色河AR1监测站观测记录的蜉蝣丰度的18年时间序列(每年5次重复),包含2个变量的90个观察值。
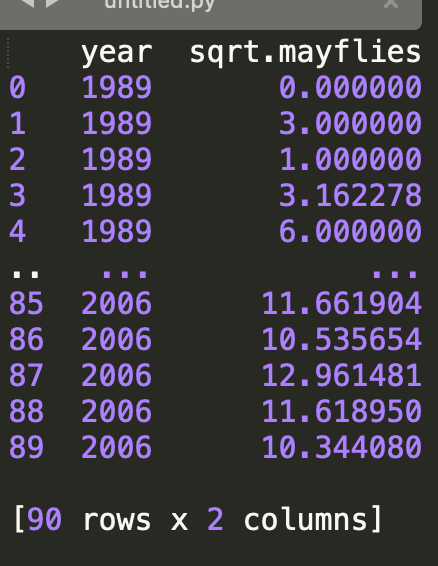
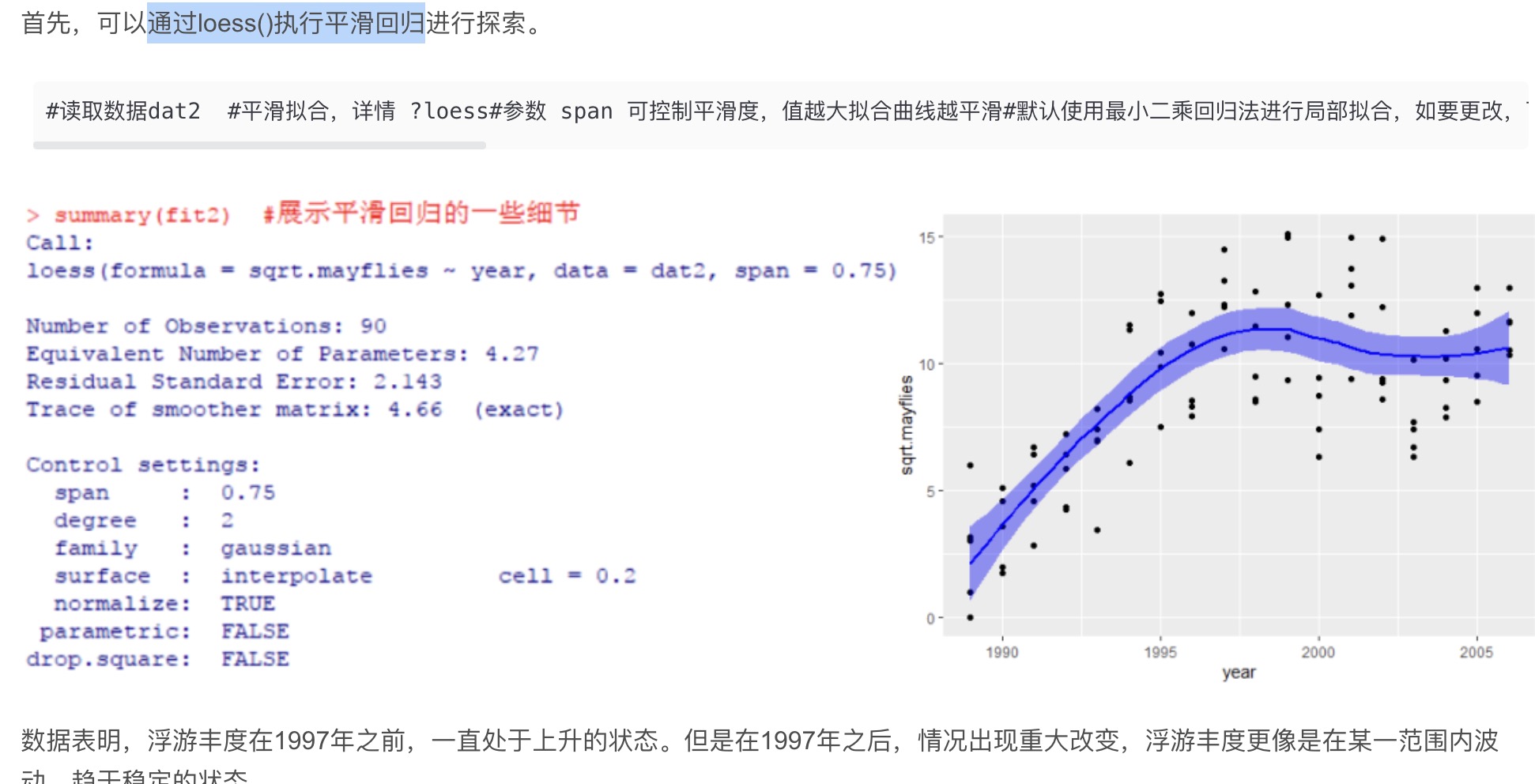
year是观测年限;sqrt.mayflies是浮游丰度的平方根。现在期望获知,在这16年期间内,浮游丰度发生了怎样的变化,以便后续结合当地水文环境特征进行一些合理的解释。使用R语言完成平滑回归。
xiaojun帮我用python也画出来了。
import pandas as pd
import numpy as np
import statsmodels.api as sm
import math
import pylab as pl
import matplotlib.pyplot as plt
data = pd.read_csv('./Arkansas.csv',encoding='utf-8')
x = data['year']
y = data['sqrt.mayflies']
lowess = sm.nonparametric.lowess
yest = lowess(y, x, frac=0.4)[:,1]
pl.clf()
pl.scatter(x, y,color = '#88c999')
#pl.plot(x, y, label='y noisy')
pl.plot(x, yest, label='y pred')
new_ticks = np.arange(1989, 2007, 1)
pl.xticks(new_ticks)
pl.legend()
pl.show()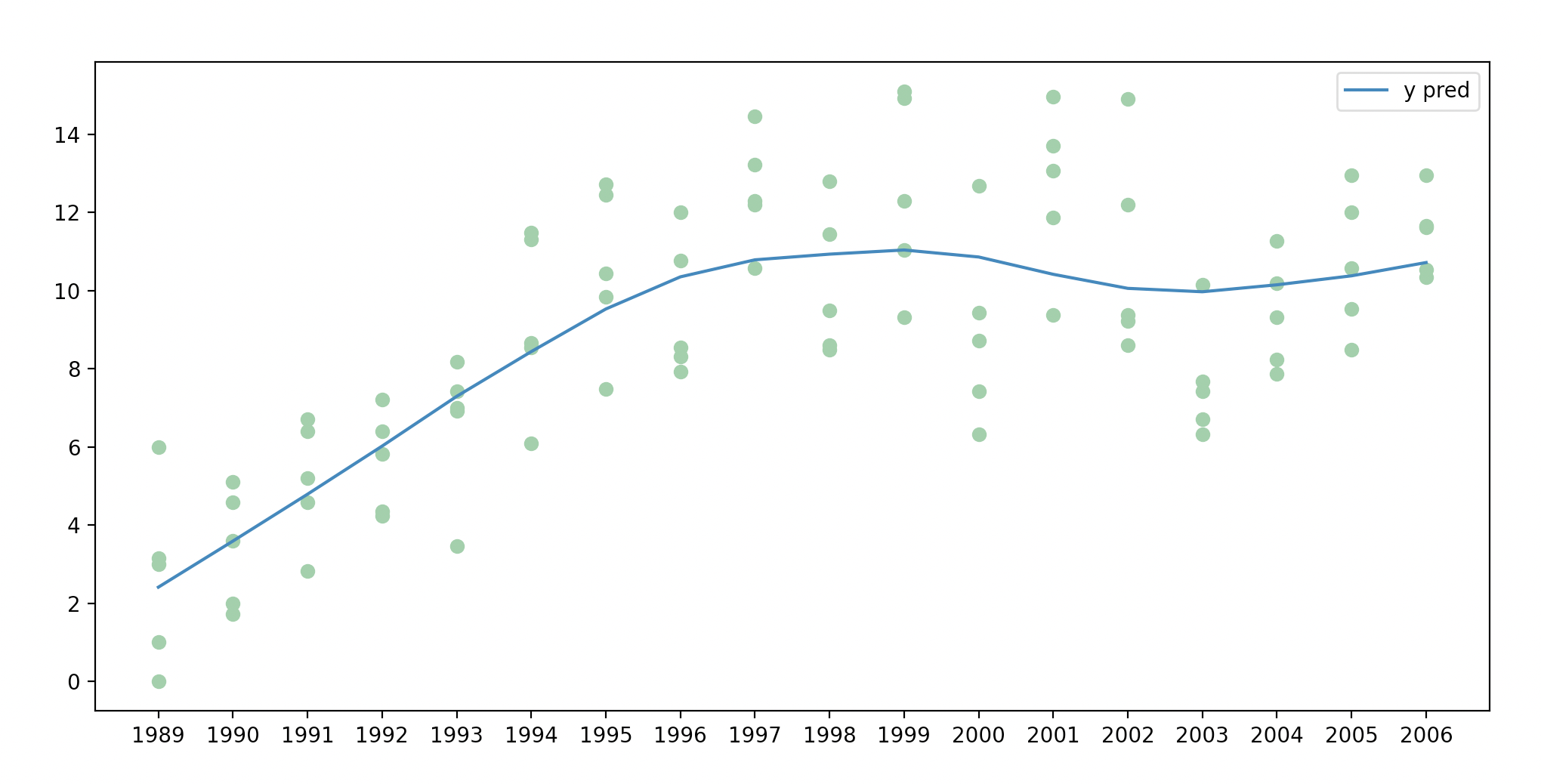
或者需要使用包plotnine,pip install plotnine。https://plotnine.readthedocs.io,可能这种更符合。
from plotnine import *
import pandas as pd
data = pd.read_csv('./Arkansas.csv',encoding='utf-8')
x = data['year']
y = data['sqrt.mayflies']
p =(
ggplot(data,aes(x='year', y='sqrt.mayflies'))
+ geom_point()
+ stat_smooth(data, span = 0.75, method = 'loess',se =True, level = 0.95,color='blue',fill = 'blue')
)
print(p)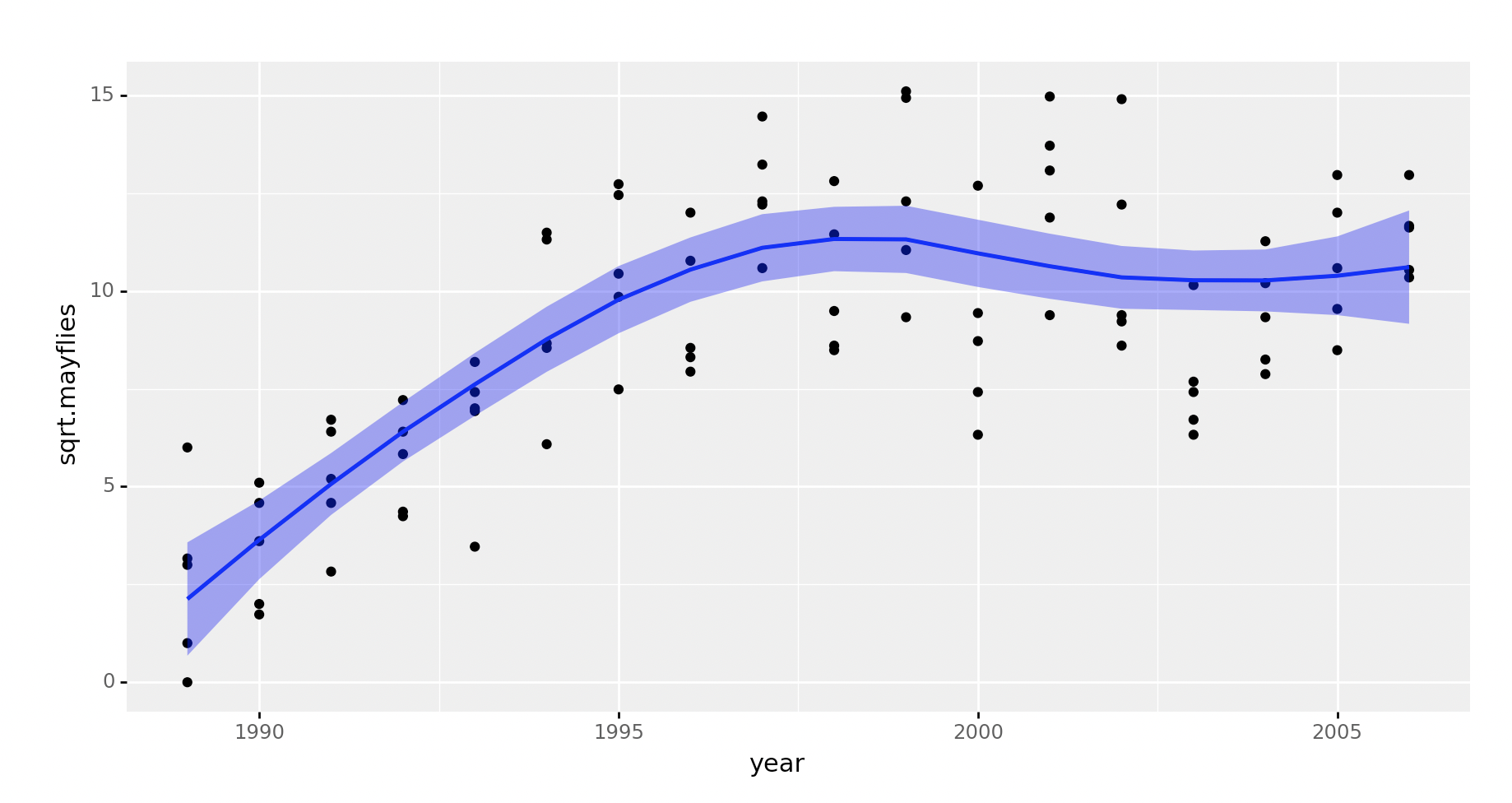
用R语言分段回归
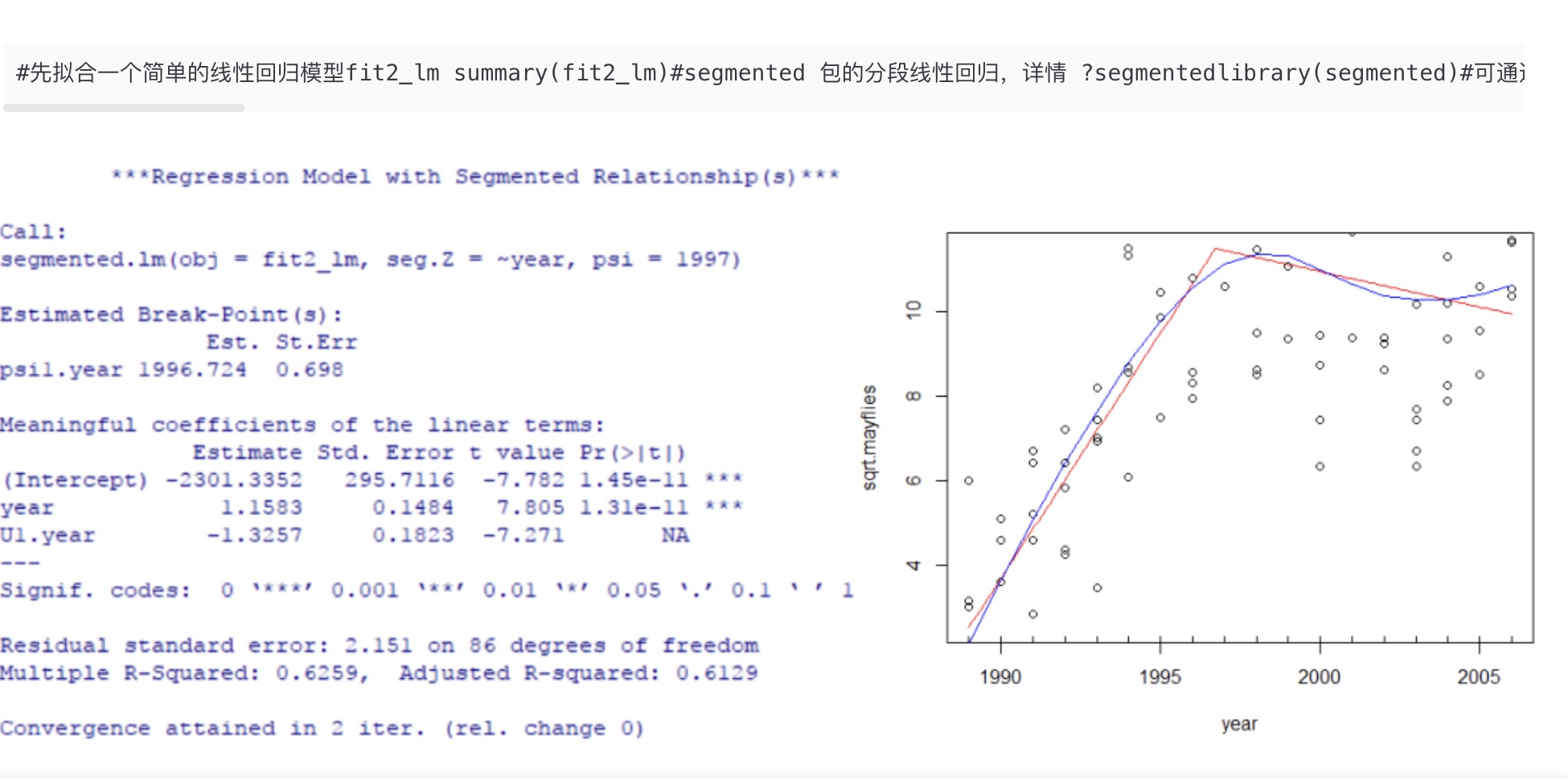
还没有学会……
原创文章(本站视频密码:66668888),作者:xujunzju,如若转载,请注明出处:https://zyicu.cn/?p=11953
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫