

Abstract
Background: Large language models (LLMs) show increasing potential for their use in healthcare for administrative support and clinical decision making. However, reports on their performance in critical care medicine is lacking.
背景:大型语言模型(LLMs)在医疗保健领域用于行政支持和临床决策制定的潜力日益增加。然而,关于其在重症医学领域表现的报告尚有不足。
Methods: This study evaluated five LLMs (GPT-4o, GPT-4o-mini, GPT-3.5-turbo, Mistral Large 2407 and Llama 3.1 70B) on 1181 multiple choice questions (MCQs) from the gotheextramile.com database, a comprehensive database of critical care questions at European Diploma in Intensive Care examination level. Their performance was compared to random guessing and 350 human physicians on a 77-MCQ practice test. Metrics included accuracy, consistency, and domain-specific performance. Costs, as a proxy for energy consumption, were also analyzed.
方法:本研究对五种大型语言模型(GPT-4o、GPT-4o-mini、GPT-3.5-turbo、Mistral Large 2407和Llama 3.1 70B)进行了评估,使用了gotheextramile.com数据库中的1181道多项选择题(MCQs)。该数据库是一个涵盖欧洲重症医学文凭考试水平的重症医学问题的综合数据库。这些模型的表现与随机猜测以及350名人类医生在77道MCQ练习测试中的表现进行了比较。评估指标包括准确率、一致性以及特定领域的表现。此外,还分析了成本,将其作为能源消耗的代理指标。
Results: GPT-4o achieved the highest accuracy at 93.3%, followed by Llama 3.1 70B (87.5%), Mistral Large 2407 (87.9%), GPT-4o-mini (83.0%), and GPT-3.5-turbo (72.7%). Random guessing yielded 41.5% (p < 0.001). On the practice test, all models surpassed human physicians, scoring 89.0%, 80.9%, 84.4%, 80.3%, and 66.5%, respectively, compared to 42.7% for random guessing (p < 0.001) and 61.9% for the human physicians. However, in contrast to the other evaluated LLMs (p < 0.001), GPT-3.5-turbo’s performance did not significantly outperform physicians (p = 0.196). Despite high overall consistency, all models gave consistently incorrect answers. The most expensive model was GPT-4o, costing over 25 times more than the least expensive model, GPT-4o-mini.
结果:GPT-4o的准确率最高,达到93.3%,其次是Llama 3.1 70B(87.5%)、Mistral Large 2407(87.9%)、GPT-4o-mini(83.0%)和GPT-3.5-turbo(72.7%)。随机猜测的准确率为41.5%(p < 0.001)。在练习测试中,所有模型的表现均优于人类医生,分别得分为89.0%、80.9%、84.4%、80.3%和66.5%,而随机猜测为42.7%(p < 0.001),人类医生为61.9%。然而,与其他评估的大型语言模型相比(p < 0.001),GPT-3.5-turbo的表现并未显著优于医生(p = 0.196)。尽管总体一致性较高,但所有模型均存在持续错误回答的情况。成本最高的模型是GPT-4o,其成本是成本最低的模型GPT-4o-mini的25倍以上。
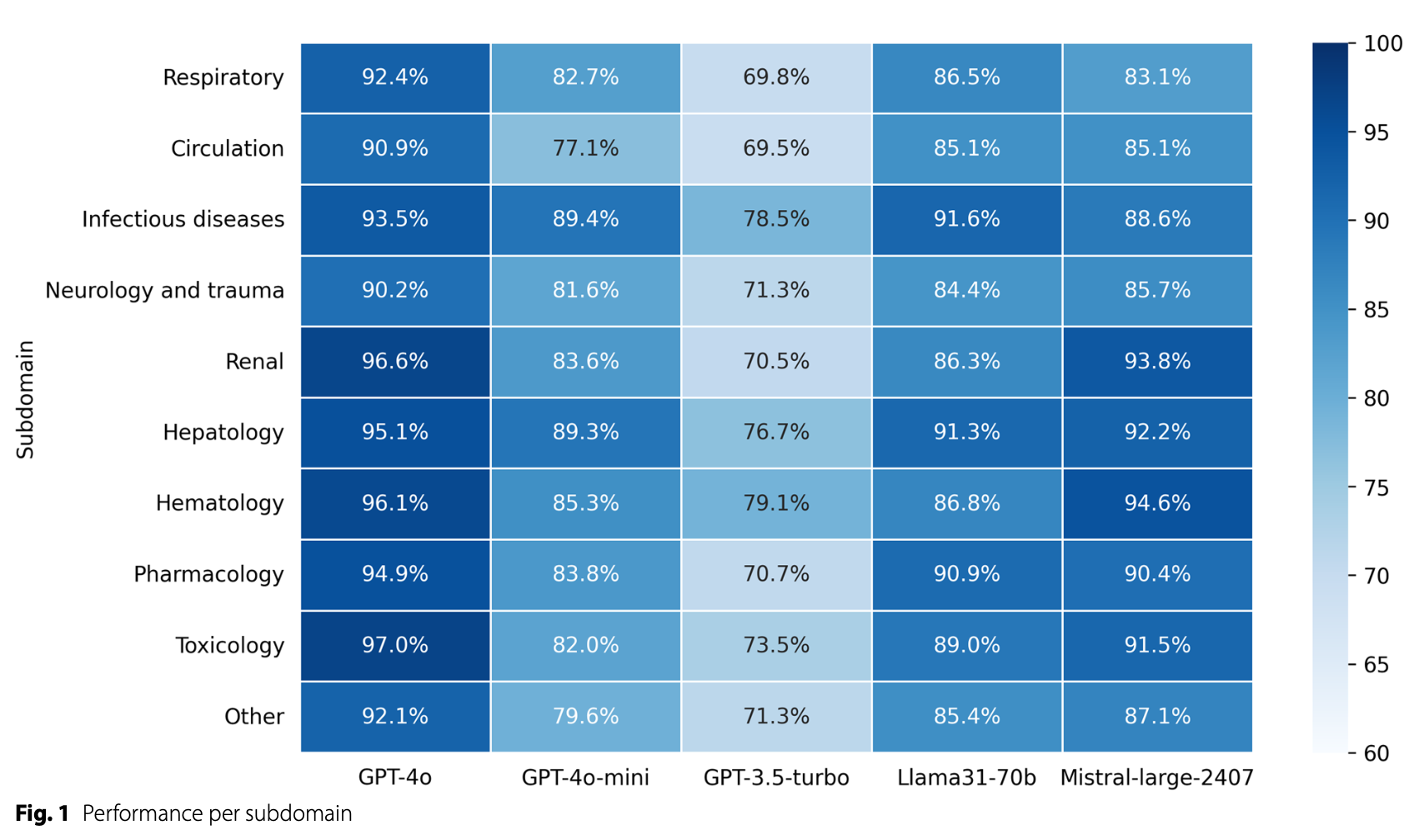
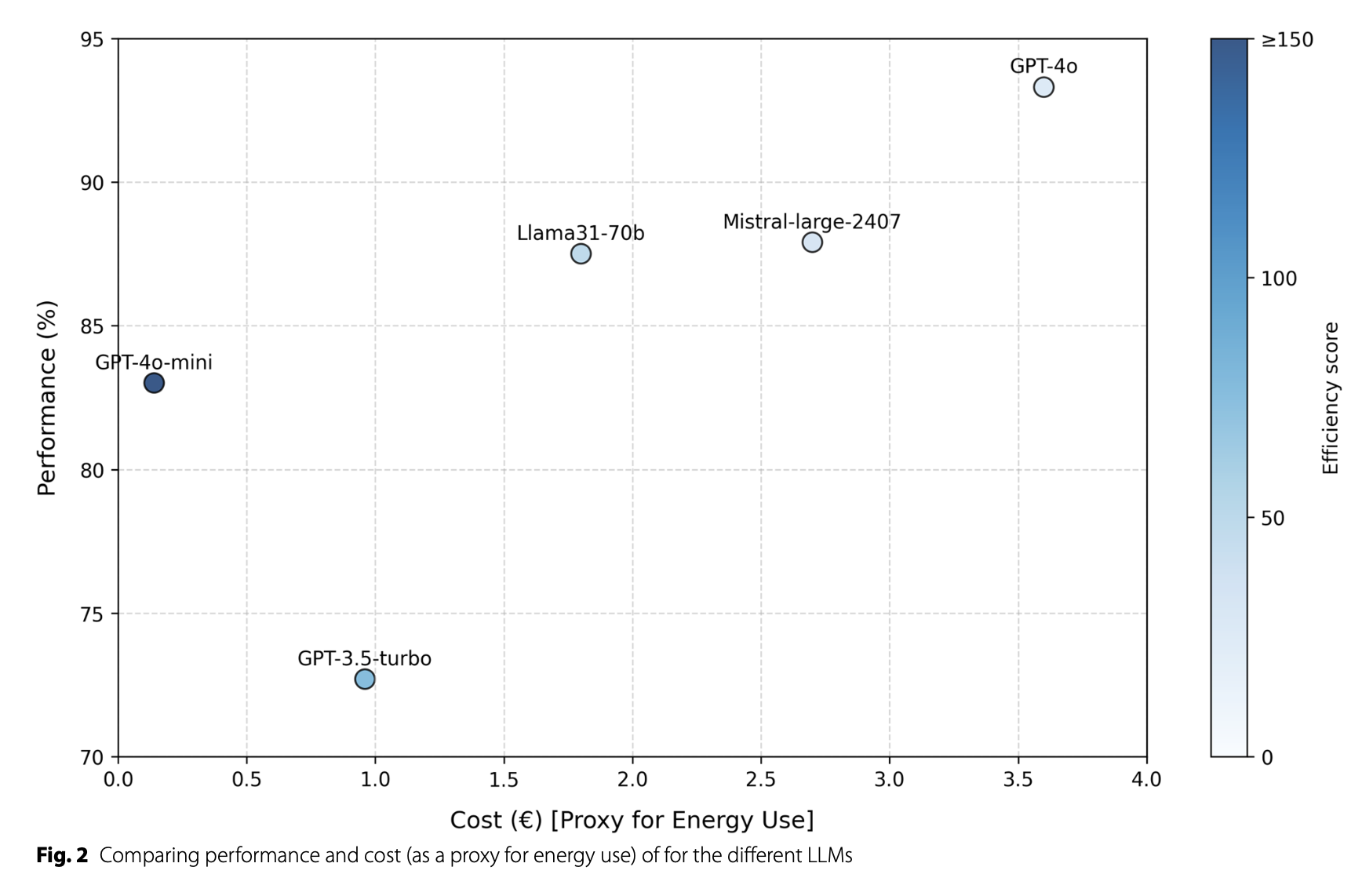

Conclusions: LLMs exhibit exceptional accuracy and consistency, with four outperforming human physicians on a European-level practice exam. GPT-4o led in performance but raised concerns about energy consumption. Despite their potential in critical care, all models produced consistently incorrect answers, highlighting the need for more thorough and ongoing evaluations to guide responsible implementation in clinical settings.
结论:大型语言模型表现出卓越的准确性和一致性,其中四种模型在欧洲水平的实践考试中优于人类医生。GPT-4o在表现上领先,但引发了对能源消耗的担忧。尽管在重症医学领域具有潜力,但所有模型都产生了持续的错误回答,这凸显了需要进行更全面和持续的评估,以指导其在临床环境中的负责任实施。
原创文章(本站视频密码:66668888),作者:xujunzju,如若转载,请注明出处:https://zyicu.cn/?p=19825
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



