竞争风险模型是一种用于处理具有多个潜在结局的生存数据的分析方法。在这种模型中,我们关心的终点事件A与不关心的终点事件B之间存在竞争关系。cmprsk R包,是用于处理竞争风险模型的分析。它提供了对多个潜在结局的生存数据进行估计、检验和回归建模的功能。
1.加载数据
数据来自R自带数据集(survival包的mgus2),共计1341名单克隆丙种球蛋白病患者,结局事件定义为“发生浆细胞恶性肿瘤”,而某些患者在“发生浆细胞恶性肿瘤”之前因为其他原因死亡,那这些发生其他死亡的患者就无法观察到“发生浆细胞恶性肿瘤”的终点,也就是说“其他死亡”与“发生浆细胞恶性肿瘤”存在竞争风险。故采用竞争风险模型分析。
library(cmprsk)
library(survival)
dt<- mgus2
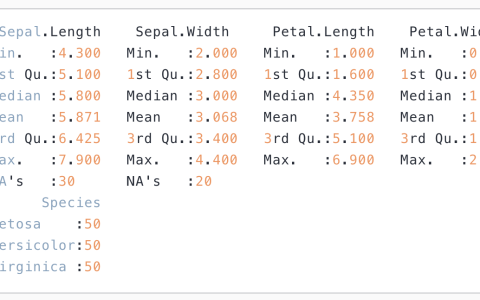
str(dt)
这里把PCM作为结局事件,death作为竞争事件
#把PCM、death是否发生和及发生时间合并到同一列
dt$etime <- ifelse(dt$pstat==0, dt$futime, dt$ptime)
dt$event <- ifelse(dt$pstat==0, 2*dt$death, 1)
dt$event <- factor(dt$event, 0:2)
table(dt$event)理解该代码:



结果如下:

0代表删失(截止日期患者既未发生PCM,也未死亡);1代表患者发生PCM;2代表发生竞争事件,患者已死亡,未能有效观察患者是否会发生PCM
2.累积发生率分析:cuminc()函数
cuminc()函数用于处理竞争风险模型的分析的工具。cuminc(ftime, fstatus, group, strata, rho=0, cencode=0,subset, na.action=na.omit)
ftime:表示失败时间的变量。
fstatus:表示不同失败原因的不同代码的变量,同时还包括一个表示被截尾观测的不同代码。
group:根据该变量的不同值计算估计值的组。测试将比较这些组。如果缺失,则视为一个组(无测试统计量)。
strata:分层变量。对估计值没有影响,但测试将在此变量上分层。
rho:测试中使用的权重函数的幂次。
cencode:表示失败时间被截尾的 fstatus 变量的值。
subset:逻辑向量,指定要包含在分析中的案例的子集。
na.action:指定对任何缺少 ftime、fstatus、group、strata 或 subset 的案例采取的操作。fit0 <- cuminc(dt$etime,dt$event,dt$sex)
print(fit0)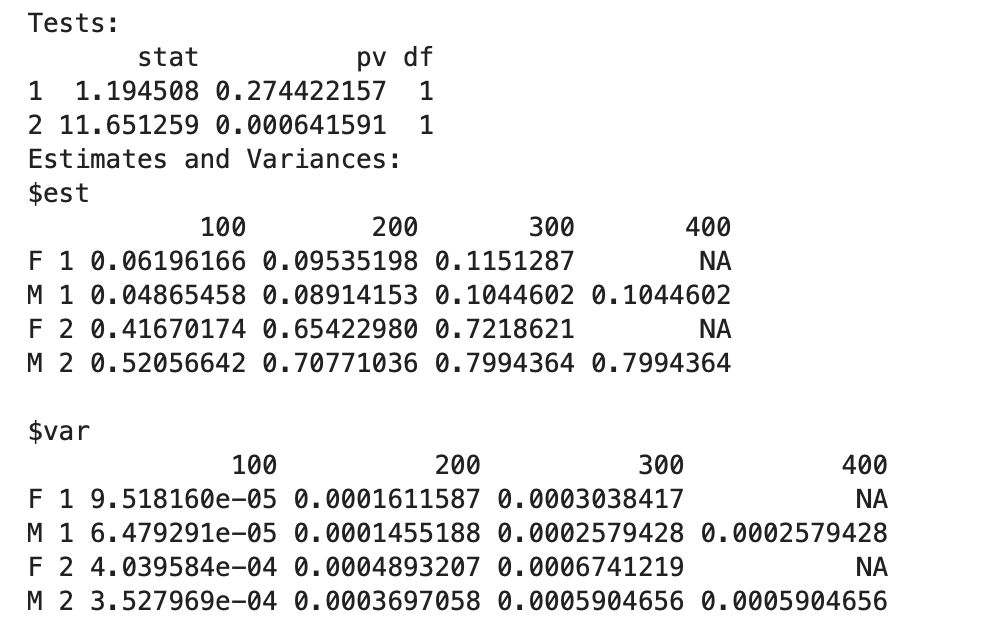
Tests 部分:第一行统计量=1.194508,P=0.274422157,表示在控制了竞争风险事件(即第二行计算的统计量和P值)后,男性和女性的累计发展为PCM的风险无统计学差异P=0.274422157
$est表示估计的各时间点男性和女性的累计发展为PCM发生率与累计竞争风险事件发生率(分别用1和2来区分,与第一行第二行一致)。
$var表示估计的各时间点男性和女性的累计发展为PCM发生率与累计竞争风险事件发生率的方差(分别用1和2来区分,与第一行第二行一致)。#画出累计PCM发生率与累计竞争风险事件发生率的生存曲线
plot(fit0,xlab = 'Month', ylab = 'CIF',lwd=2,lty=1,col = c('red','blue','black','forestgreen'))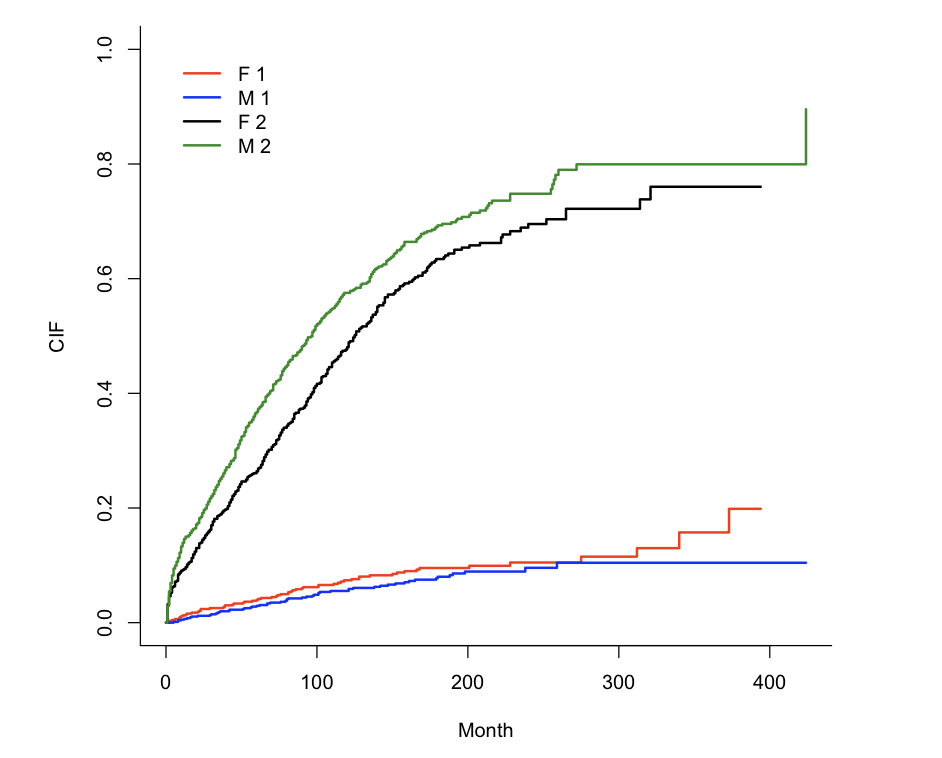
纵坐标表示累计发生率pcm,横坐标是时间轴。我们从F1对应的红色曲线和M1对应的蓝色曲线可以得出,女性组的发生pcm风险较男性组高,但未达到统计学意义,P=0.274422157。同理,F2对应的黑色曲线在M2对应的草绿色曲线下方,我们可以得出,女性组的竞争风险事件发生率较男性组低,具有统计学差异,P=0.0064。简单来讲,这个图可以用一句话来概括:在控制了竞争风险事件后,女性组和男性组累计PCM发生率无统计学差异P=0.274422157。
#ggcompetingrisks()绘制竞争风险模型的累积发生率曲线,ggplot2版本
library(survminer)
ggcompetingrisks(fit0,
gnames=c("Female PCM",
"Male PCM",
"Female Death",
"Male Death"),
gsep = " ")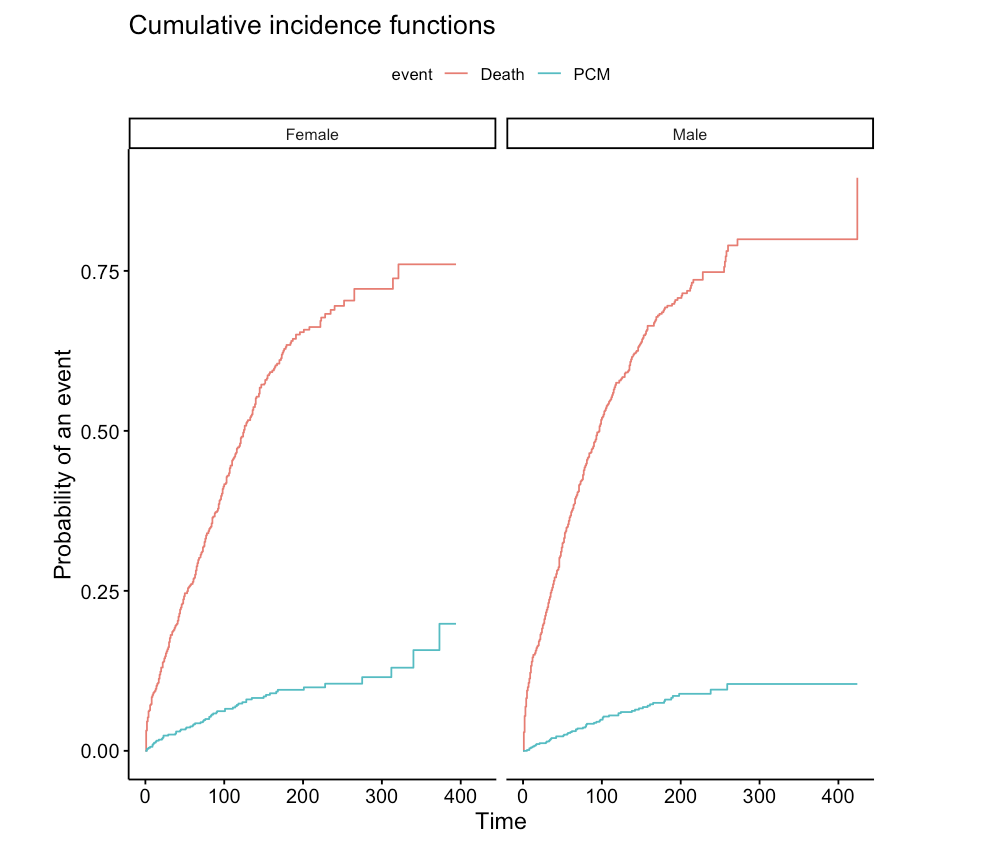
ggcompetingrisks(fit0,
multiple_panels = FALSE,
gnames=c("Female PCM",
"Male PCM",
"Female Death",
"Male Death"),
gsep = " ")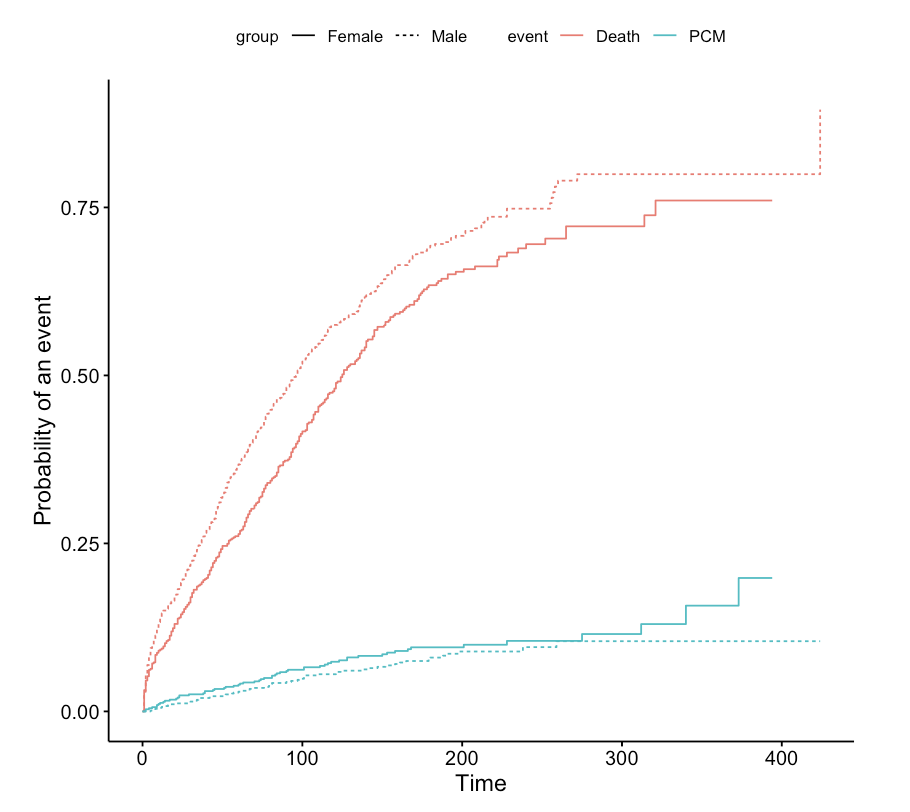
ggcompetingrisks(fit0,
conf.int = TRUE,
gnames=c("Female PCM",
"Male PCM",
"Female Death",
"Male Death"),
gsep = " ")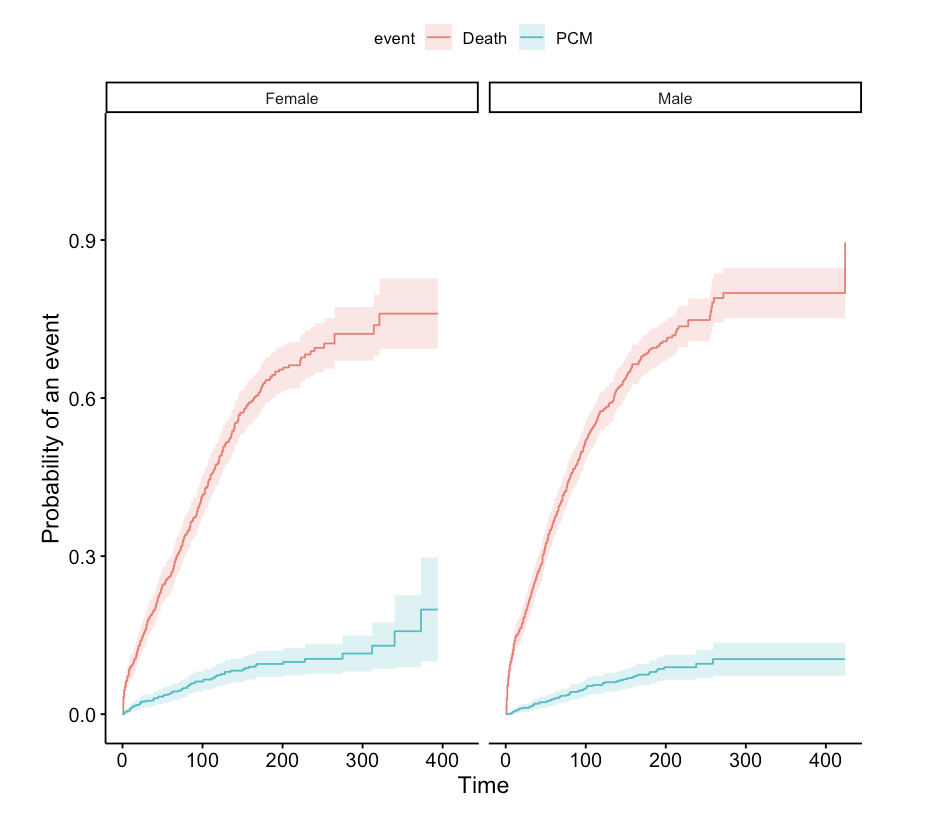
ggcompetingrisks(fit0,
multiple_panels = FALSE,
conf.int = TRUE,
gnames=c("Female PCM",
"Male PCM",
"Female Death",
"Male Death"),
gsep = " ")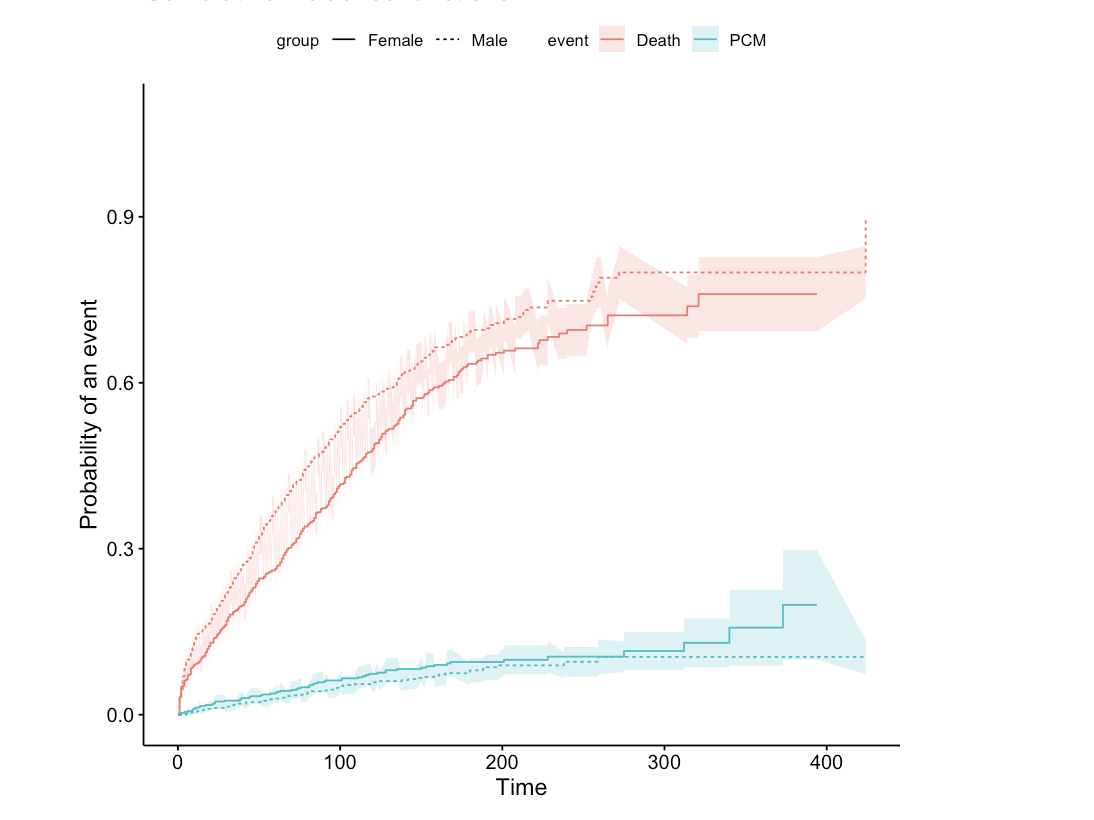
3.竞争风险模型(多因素分析):crr()函数
- 3.1 cmprsk包中crr()函数可以很方便的实现多因素分析:crr(ftime, fstatus, cov1, cov2, tf, cengroup, failcode=1, cencode=0,subset, na.action=na.omit, gtol=1e-06, maxiter=10, init, variance=TRUE)
- ftime:表示失败时间的变量。
- fstatus:表示不同失败原因的不同代码的变量,同时还包括一个表示被截尾观测的不同代码。
- cov1:固定协变量的矩阵(nobs x ncovs)。
cov1、cov2或两者都需要提供。 - cov2:将与时间函数相乘的协变量的矩阵。如果使用,通常这些协变量也会出现在
cov1中,以获得比例风险效应和时间交互作用。 - tf:时间函数。这是一个接受时间向量作为参数的函数,并返回一个矩阵,其第 j 列是在输入时间向量处评估的与第 j 列
cov2对应的时间函数的值。在时间 tk 处,模型包括术语cov2[,j]*tf(tk)[,j]作为协变量。 - cengroup:为每个组提供不同值的向量,其中包含不同的截尾分布(截尾分布在这些组内分别估计)。如果数据都在一个组内,则为缺失。
- failcode:表示感兴趣的失败类型的 fstatus 代码。
- cencode:表示被截尾观测的 fstatus 代码。
- subset:逻辑向量,指定要包含在分析中的案例的子集。
- na.action:指定对任何缺少
ftime、fstatus、cov1、cov2、cengroup或subset的案例采取的操作。 - gtol:当梯度函数的某个函数小于
gtol时,迭代停止。 - maxiter:牛顿算法中的最大迭代次数(0 表示在
init处计算得分和方差,但不执行迭代)。 - init:回归参数的初始值(默认为全 0)。
- variance:如果为 FALSE,则不计算方差估计和残差。
crr 函数返回一个类为 crr 的列表,包含以下组件:
– $coef:估计的回归系数。
– $loglik:在 coef 处评估的对数伪似然。
– $score:在 coef 处评估的对数伪似然的导数。
– $inf:对数伪似然的二阶导数。
– $var:回归系数的估计方差协方差矩阵。
– $res:给出每个唯一失败时间点(行)上每个得分的贡献(列)的残差矩阵。
– $uftime:唯一失败时间的向量。
– $bfitj:用于预测的基于Breslow类型估计的潜在子分布累积风险的跳跃值。
– $tfs:tfs 矩阵(如果使用了 tf())。
– $converged:迭代算法是否收敛。
– $call:调用 crr 的信息。
– $n:用于拟合模型的观测数。
– $n.missing:由于缺失值而从输入数据中删除的观测数。
– $loglik.null:当所有系数为 0 时的对数伪似然值。
cov <- data.frame(age = dt$age,
sex = ifelse(dt$sex=='M',1,0), ## 设置哑变量
hgb = dt$hgb,
creat=dt$creat,
mspike=dt$mspike)
##构建多因素的竞争风险模型。此处需要指定failcode=1, cencode=0, 分别代表结局事件赋值1与截尾赋值0,其他赋值默认为竞争风险事件2。
fit2 <- crr(dt$etime, dt$event, cov, failcode=1, cencode=0)
summary(fit2)
mspike:回归系数为 0.9068,其指数为 2.476,意味着每单位 mspike 的增加会导致风险增加 147.6%。置信区间为 (1.823, 3.365),表示我们对mspike的风险比估计值有95%的置信度在这个区间内。即在控制了竞争风险事件后,mspike是发生pcm的独立影响因素。
data<-cov[15,]
predict_crr<- predict.crr(fit2, data)
plot(predict_crr)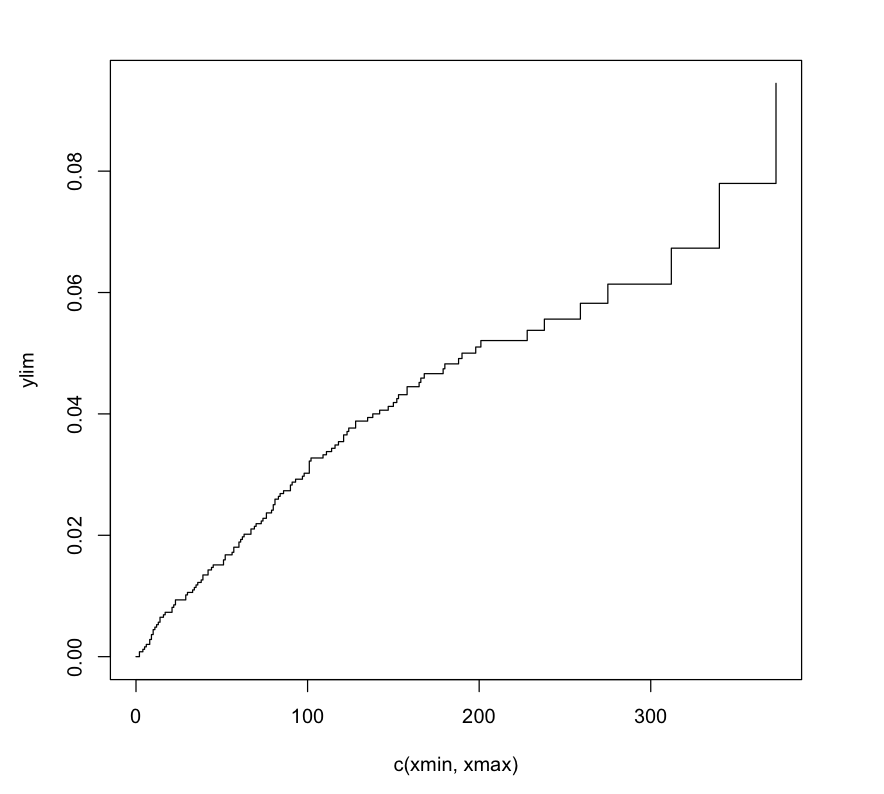
特别申明:本文为转载文章,转载自学习实践者,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/4qVZ0Dnm1oHPra-18TYviw
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫