
倾向性评分匹配(propensity score matching, PSM)主要是在随机对照试验(Randomized controlled trials,RCT)中用于衡量treat组和control组样本的其他各项特征(如年龄、体重、身高、人种等)的整体均衡性的度量。比如说研究一种药物对疾病的影响,在临床实验中,treat组和control组除了使用药物(安慰剂)不同外,其他的临床特征(如年龄、体重等)都应该基本是相似的,这样treat和control组才有可比性,进而才能验证药物的有效性。
如下图所示,该治疗方法实际上是无效的,但是由于分组中年龄的不平衡导致得出错误的结论。
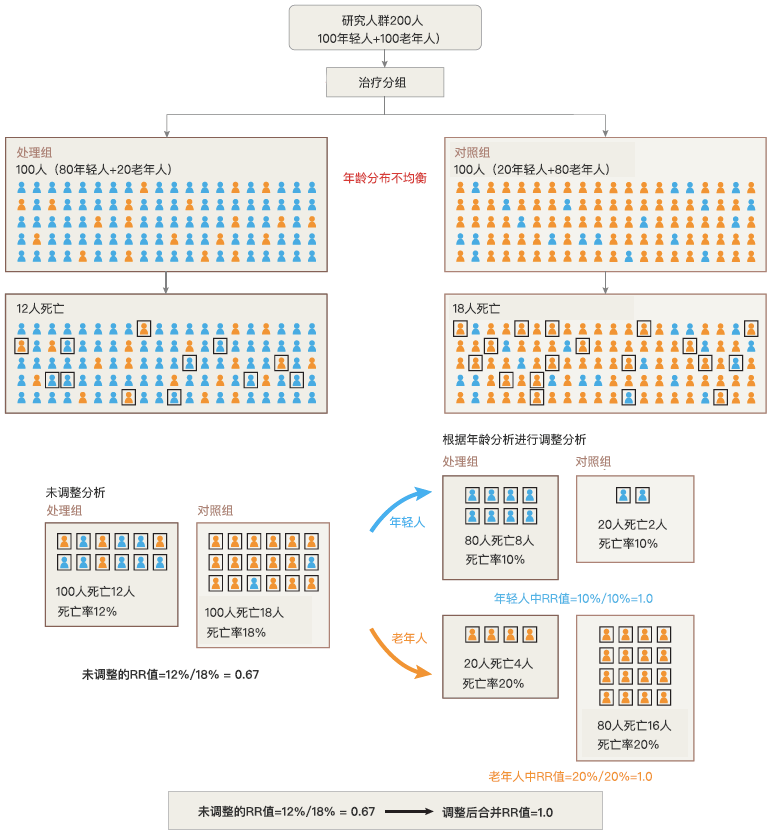
RR值,(Risk Ratio)称为相对危险度,或者危险比,实质就是两个率的比,是两组真实发病率、患病率或死亡率的比值。我们在讨论RR值的意义时,应该把RR值和1比,>1者是患病、死亡的危险因素,反之,是保护因素。
1、导入模块
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format='retina'
import numpy as np
import pandas as pd
import seaborn as sns
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
%watermark -a 'xujun' -d -t -v -p numpy,scipy,pandas,sklearn,matplotlib,seaborn
2、导入数据
num_cols = ['age','sofa']
cat_cols = ['first_careunit','echo','gender','mort_28_day','icd_chf']
dtype = {col: 'category' for col in cat_cols}
df = pd.read_csv('./merged_data.csv',dtype=dtype)
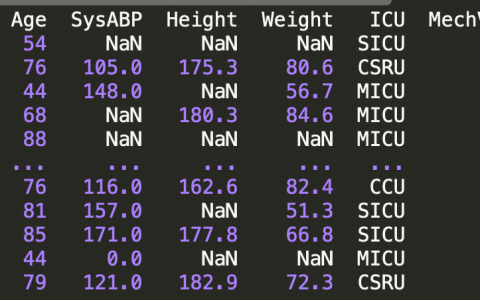
df.head()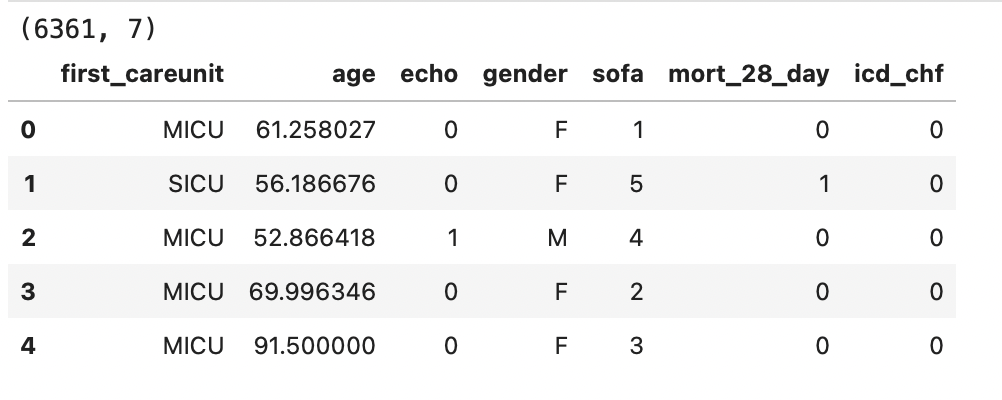
3、将分类变量的那一列转换为0,1,2,…等
col_mappings = {}
for col in ('first_careunit','echo','gender','mort_28_day','icd_chf'):
col_mapping = dict(enumerate(df[col].cat.categories))
col_mappings[col] = col_mapping
print(col_mappings)
for col in ('first_careunit','echo','gender','mort_28_day','icd_chf'):
df[col] = df[col].cat.codes
df.head()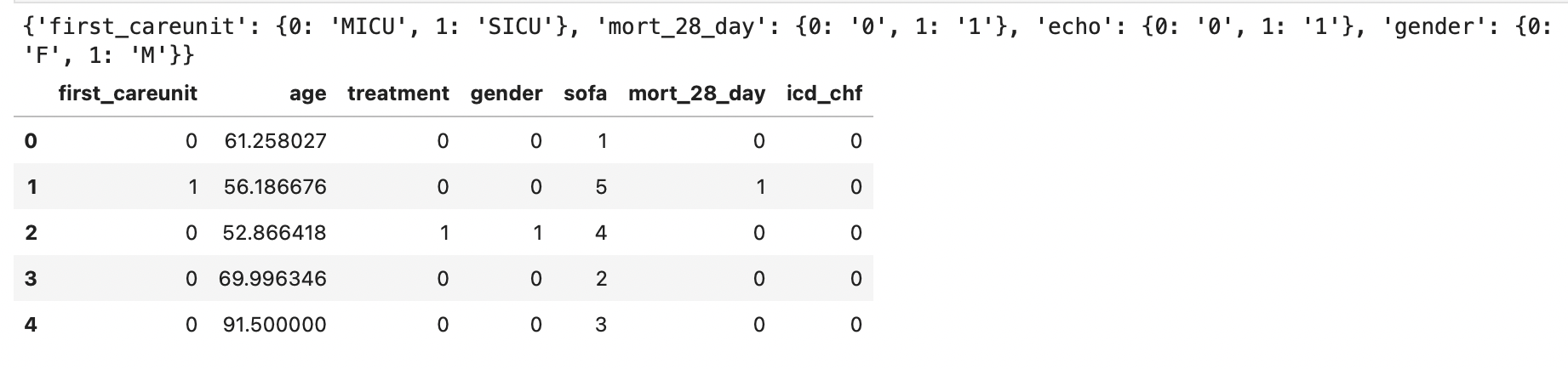
features = df.columns.tolist() # 转为列表
features.remove('echo') # remove treatment
features.remove('mort_28_day') # remove outcome
agg_operations = {'echo': 'count'}
agg_operations.update({
feature: ['mean', 'std'] for feature in features
})
table_one = df.groupby('echo').agg(agg_operations)
table_one.head()
def compute_table_one_smd(table_one: pd.DataFrame, round_digits: int=4) -> pd.DataFrame:
feature_smds = []
for feature in features:
feature_table_one = table_one[feature].values
neg_mean = feature_table_one[0, 0]
neg_std = feature_table_one[0, 1]
pos_mean = feature_table_one[1, 0]
pos_std = feature_table_one[1, 1]
smd = (pos_mean - neg_mean) / np.sqrt((pos_std ** 2 + neg_std ** 2) / 2)
smd = round(abs(smd), round_digits)
feature_smds.append(smd)
return pd.DataFrame({'features': features, 'smd': feature_smds})
table_one_smd = compute_table_one_smd(table_one)
table_one_smd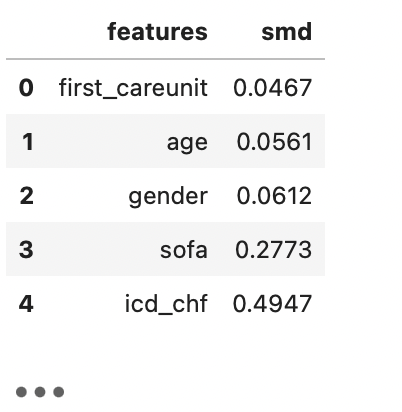
#回归
logistic = LogisticRegression(solver='liblinear')
logistic.fit(data, treatment)
#预测
pscore = logistic.predict_proba(data)[:, 1]
pscore
#得分
roc_auc_score(treatment, pscore)mask = treatment == 1
pos_pscore = pscore[mask]
neg_pscore = pscore[~mask]
print('treatment count:', pos_pscore.shape)
print('control count:', neg_pscore.shape)结果:treatment count: (3262,) control count: (3099,)
# 画图
plt.rcParams['figure.figsize'] = 8, 6
plt.rcParams['font.size'] = 12
sns.distplot(neg_pscore, label='control')
sns.distplot(pos_pscore, label='treatment')
plt.xlim(0, 1)
plt.title('Propensity Score Distribution of Control vs Treatment')
plt.ylabel('Density')
plt.xlabel('Scores')
plt.legend()
plt.tight_layout()
plt.show()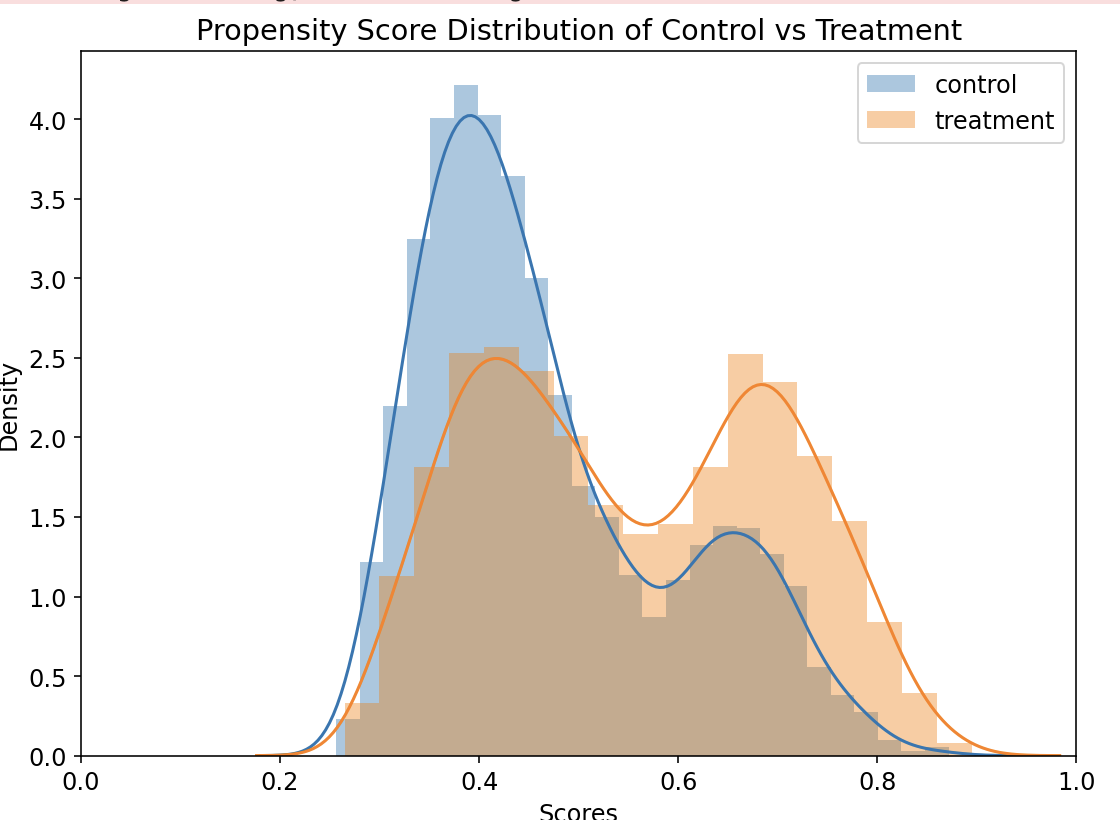
def get_similar(pos_pscore: np.ndarray, neg_pscore: np.ndarray, topn: int=5, n_jobs: int=1):
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(n_neighbors=topn + 1, metric='euclidean', n_jobs=n_jobs)
knn.fit(neg_pscore.reshape(-1, 1))
distances, indices = knn.kneighbors(pos_pscore.reshape(-1, 1))
sim_distances = distances[:, 1:]
sim_indices = indices[:, 1:]
return sim_distances, sim_indices
sim_distances, sim_indices = get_similar(pos_pscore, neg_pscore, topn=1)
sim_indices_, counts = np.unique(sim_indices[:, 0], return_counts=True)
np.bincount(counts)#重新把echo和mort_28_day这两列弄回到df_cheaned中
df_cleaned['echo'] = treatment
df_cleaned['mort_28_day'] = death
df_pos = df_cleaned[mask]
df_neg = df_cleaned[~mask].iloc[sim_indices[:, 0]]
df_matched = pd.concat([df_pos, df_neg], axis=0)
df_matched.head()table_one_matched = df_matched.groupby('mort_28_day').agg(agg_operations)
table_one_smd_matched = compute_table_one_smd(table_one_matched)
table_one_smd_matchednum_matched_pairs = df_neg.shape[0]
print('number of matched pairs: ', num_matched_pairs)
# pair t-test
stats.ttest_rel(df_pos['mort_28_day'].values, df_neg['mort_28_day'].values)number of matched pairs: 3262 Ttest_relResult(statistic=-7.974066292969522, pvalue=2.1050737386146504e-15)
data_final = pd.DataFrame()
df_pos = df[mask]
df_neg = df[~mask].iloc[sim_indices[:, 0]]
data_final = pd.concat([df_pos, df_neg], axis=0)
data_final.to_csv('merged_data_final.csv', index=False)然后重新导入merged_data_final.csv,画图看看
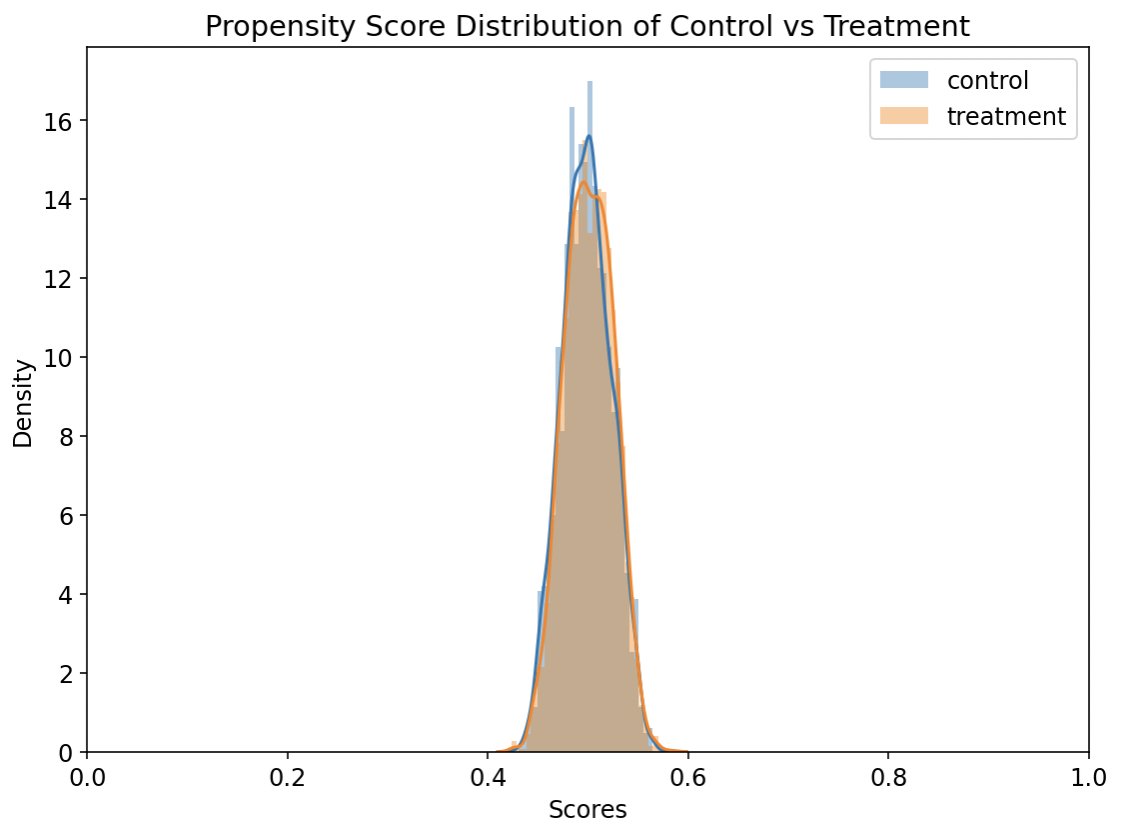
特别申明:本文为转载文章,转载自,不代表贪吃的夜猫子立场,如若转载,请注明出处:http://ethen8181.github.io/machine-learning/ab_tests/causal_inference/matching.html#The-Definition-of-Causal-Effect
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

Comments(2)
您好!请问 df_cleaned是什么呀 期待回复
@1292:cat_cols = [CAT1]
df_one_hot = pd.get_dummies(df[cat_cols], drop_first=True)
df_cleaned = pd.concat([df[num_cols], df_one_hot, df[[SEX, TREATMENT, DEATH]]], axis=1)
df_cleaned.head()
可能被我跳过了,去看原始的http://ethen8181.github.io/machine-learning/ab_tests/causal_inference/matching.html#The-Definition-of-Causal-Effect