
综合比较微信工作号的几篇爬虫文章,用Python批量下载文献,真香!、爬取Pubmed论文基本信息和Python 批量爬取 Pubmed 文献,觉得第一篇最实用了,亲测可行,加上强大的SCI-hub实在有点方便的。再来转发一下这一篇文章,讲述关于Sci-Hub的历史,Sci-Hub十岁生日解封,超233万新论文被放出!总数达到近8800万。

话不多说,还是上爬虫代码:
import requests
from lxml import etree
import time
import re
#对某个查询词进行爬取,获取搜索得到的结果数
def get_results(term):
url = f'https://pubmed.ncbi.nlm.nih.gov/?term={term}'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36",
}
r = requests.get(url, headers=headers)
r.encoding = 'utf-8'
tree = etree.HTML(r.text)
results = tree.xpath('//div[@class="results-amount"]/span/text()')
if len(results) !=0:
new_results = str(results[0]).replace("\n","")
print(f"一共找到{new_results}个结果")
end_results = int(new_results.replace(",",""))#字符串中含有,号无法转换成数字,我们用空来替代它
if end_results % 10 == 0:
pages = end_results / 10
else:
pages = int(end_results/10)+1
print(f"一共有{str(pages)}页结果")
else:
print("没有结果")
pages = 0
return pages
#爬取到文章的标题以及它的doi号(“科技论文的身份证”)
def get_links(term,pages):
total_list = []
for i in range(pages):
url = f'https://pubmed.ncbi.nlm.nih.gov/?term={term}&page={str(i+1)}'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36",
}
r = requests.get(url,headers=headers)
r.encoding='utf-8'
tree =etree.HTML(r.text)
links = tree.xpath('//div[@class="docsum-content"]/a/@href')
for link in links:
#构造单个文献的链接
new_link = 'https://pubmed.ncbi.nlm.nih.gov' + link
total_list.append(new_link)
time.sleep(3)
return total_list
#形成DOI的list列表
def get_message(total_list):
doi_list = []
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"
}
for url in total_list:
r = requests.get(url, headers=headers)
r.encoding = 'utf-8'
tree = etree.HTML(r.text)
title = tree.xpath('//h1[@class="heading-title"]/text()')[0]
new_title = str(title).replace("\n", "")
print(new_title[26:])
doi = tree.xpath('//span[@class="citation-doi"]/text()')
if len(doi) == 0:
print("这篇文章没有doi号")
else:
new_dois = str(doi[0]).replace(" ", "")
new_doi = new_dois[5:-2]
doi_list.append(new_doi)
print(f"这篇文章的doi号是:{new_doi}")
return doi_list
#根据doi号链接到sci-hub,下载文献到本地,保存为doi号.pdf
def get_content(dois):
for doi in dois:
urls = f'https://sci.bban.top/pdf/{doi}.pdf#view=FitH'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"
}
r = requests.get(urls, headers=headers)
title = re.findall("(.*?)/",doi)
with open(f"{title[0]}.pdf",'wb')as f:
f.write(r.content)
time.sleep(2)
if __name__ == '__main__':
term = input("请输入文献的关键词(英文):")
print("正在寻找文献中....")
if get_results(term) != 0:
page = int(input("请输入下载的页数:"))
print("正在下载文献,注意只能下载含doi号的文献")
get_content(get_message(get_links(term=term,pages=page)))
print("下载已完成")
else:
print("对不起,没有文献可以下载")
运行结果如下:
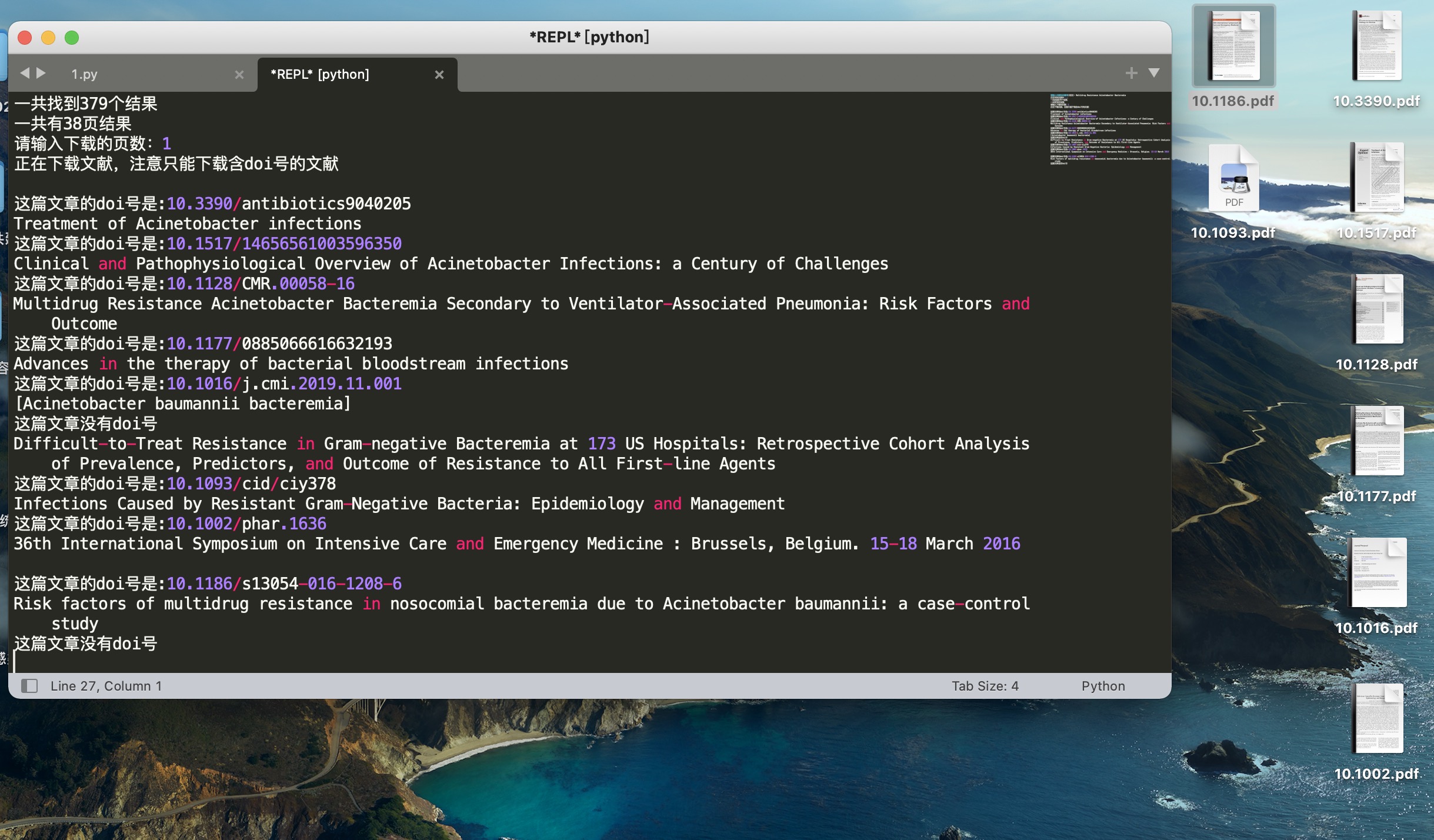
亲测可行。当然你也可从pubmed上输出然后导入zotero软件,然后利用软件里面的查到可用的pdf功能,但是这个不会从scihub中查找并下载。
原创文章(本站视频密码:66668888),作者:xujunzju,如若转载,请注明出处:https://zyicu.cn/?p=7535
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


Comments(2)
运行显示错误,ModuleNotFoundError: No module named ‘lxml’,请问是否前面有自定义模块1xml部分的代码?
@0284:这个是包咯,不建议去批量下载,你的ip地址会被锁死