逆概率处理加权(Inverse Probability of Treatment Weighting, IPTW) 或逆处理概率加权(Inverse Probability of Weighting, IPW)就是将评分的倒数作为权重。

代码过程:
1. 载入R包和数据
library(tableone)#制作基线表
library(survey)#提取加权结果
library(reshape2)#画SMD
rm(list = ls())#清理环境
#载入数据,本数据status==0为死亡(652人)
aa <- read.csv('R15.csv',header = T,row.names = NULL,stringsAsFactors = F)
#因子变量转换
for (i in names(aa)[c(1,3,5:11)]){aa[,i] <- as.factor(aa[,i])}2. 设定混杂因素
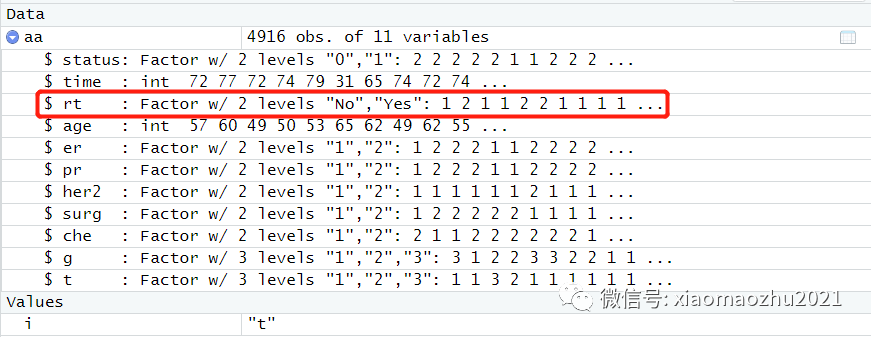
#本例数据,status为结局事件,0为死亡,time=随访事件,rt (放疗)为研究对象,其他因素均为混杂因素
vars=c( "age", "er", "pr", "her2", "surg", "che", "g", "t") 3. 未加权的Table 1
#CreateTableOne()函数构建基线表,rt作为分类项
tab_Unmatched <- CreateTableOne(vars = vars,
strata = "rt",
data = aa,
test =T)
#展示标准化平均差,SMD
print(tab_Unmatched,showAllLevels=TRUE,smd = TRUE)
#查看有无SMD>10%
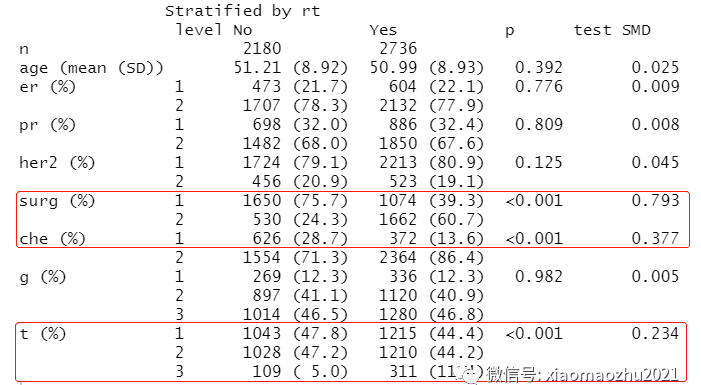
addmargins(table(ExtractSmd(tab_Unmatched) > 0.1))备注:可以发现手术(surg)、化疗(che)、T分期(t)这3个混杂因素在rt两组中非常不平衡,卡方检验p<0.001,SMD>10%。(标准化平均差大于10%,这通常被认为是变量不平衡)
4. 基于IPTW的Table 1
#建模并计算PS
psModel=glm(rt~age+er+pr+her2+surg+che+g+t,
family=binomial(link="logit"),
data=aa)
#PS
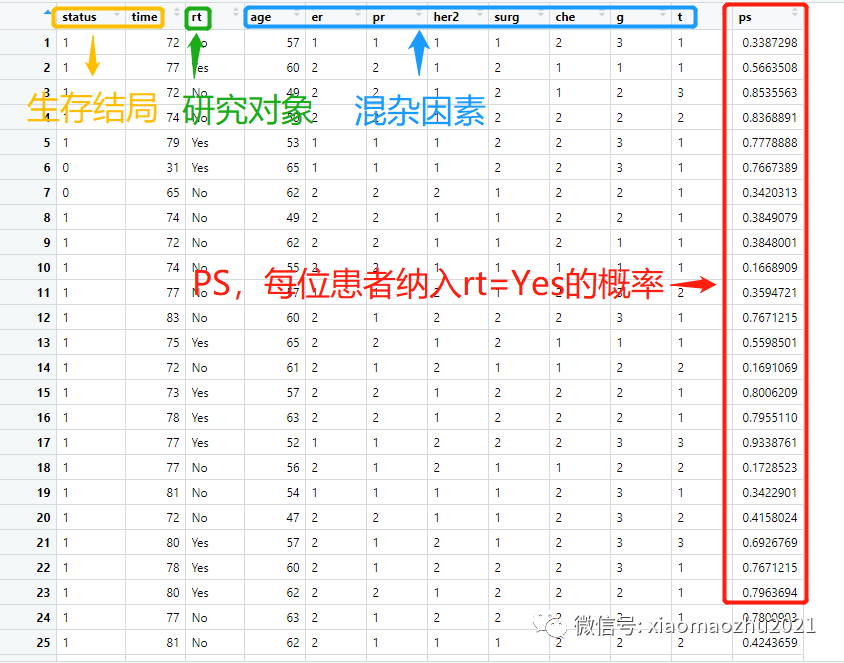
aa$ps=predict(psModel,type="response")我们已经说过PS的本质是个概率,是在存在混杂因素的条件下,患者被纳入治疗组(y=1)的概率。所以,PS模型本质上是个多因素逻辑回归模型,y为研究对象,x为混杂因素。因此,我们用predict()就能计算出PS
#1-逆概率,计算治疗组和对照组的逆概率
#根据1/PS和1/1-PS
aa$wt1=1/aa$ps
aa$wt0=1/(1-aa$ps)
#2-根据公式计算所有患者的权重
#假如患者为治疗组(Yes)用公式1加权,否则用公式2加权
aa$w <- ifelse(aa$rt=="Yes",aa$wt1,aa$wt0)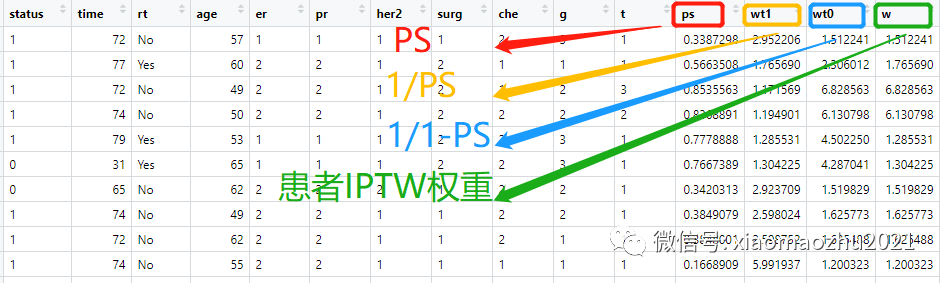
#1-提取IPTW后的数据
dataIPTW=svydesign(ids=~1,data=aa,weights= ~w)
#2-再次构建Table-1
tab_IPTW=svyCreateTableOne(vars=vars, strata="rt",data=dataIPTW,test=T)
#标准化差结果
print(tab_IPTW,showAllLevels=TRUE,smd=TRUE)
#查看是否有SMD>10%的混杂因素
addmargins(table(ExtractSmd(tab_IPTW) > 0.1))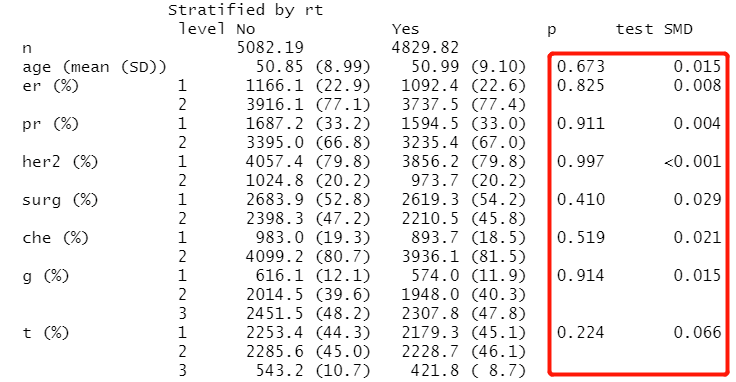
5. 标准化平均差SMD可视化
#提取作图数据
dataPlot <- data.frame(variable=rownames(ExtractSmd(tab_Unmatched)),
Unmatched=as.numeric(ExtractSmd(tab_Unmatched)),
IPTW=as.numeric(ExtractSmd(tab_IPTW))
)
#指定将要出现在图中的变量
dataPlotMelt<-melt(data= dataPlot,
id.vars=c("variable"),
variable.name= "Method",
value.name= "SMD")
#
varNames <-as.character(dataPlot$variable)[order(dataPlot$Unmatched)]
#
dataPlotMelt$variable<- factor(dataPlotMelt$variable,
levels = varNames)
#画图
ggplot(data = dataPlotMelt,
mapping = aes(x = variable, y = SMD,
group = Method,
color = Method,
shape = Method )) +
#geom_line() +
geom_point(size=4) +
geom_hline(yintercept = 0.1,
color = "red",
lty=2,
size = 0.1) +
coord_flip() +
theme_bw(base_size = 18)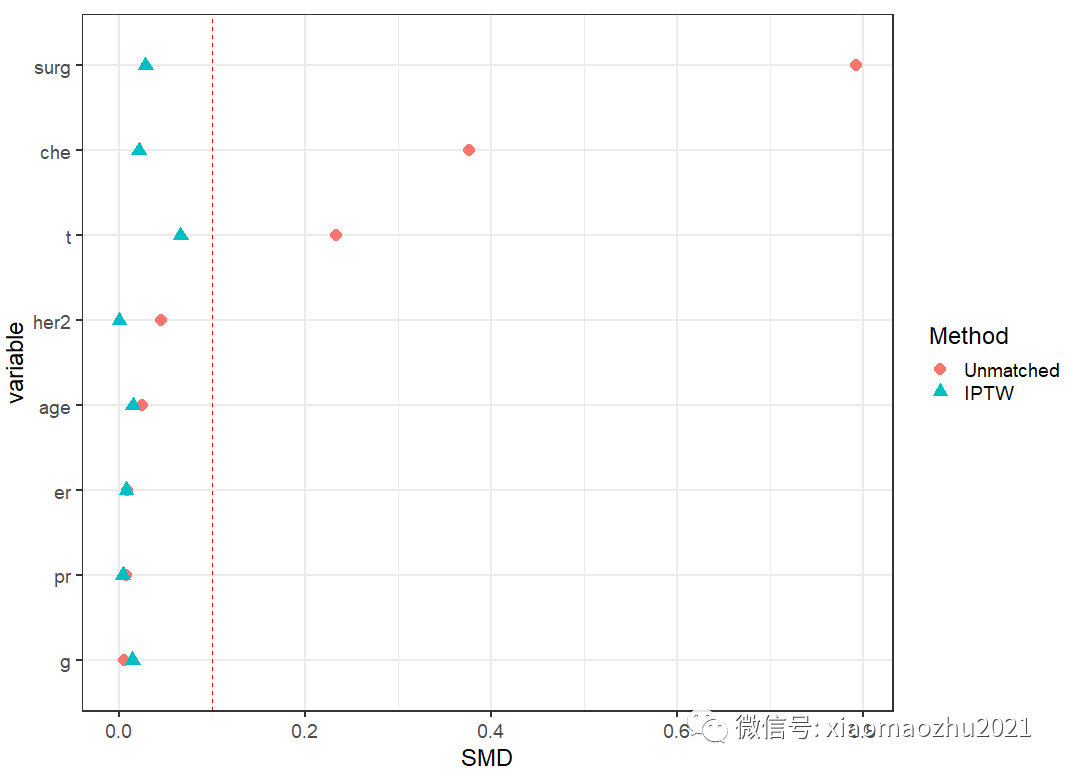
6. 两个Table 1合并输出
#1.提取两个结果
table1<- cbind(print(tab_Unmatched,printToggle =F,showAllLevels=T,),
print(tab_IPTW,printToggle =F,showAllLevels=T,)
)
# 插入一行分组
table1<- rbind(Group=rep(c("Level","RT","No-RT","P","test"),2),table1)
#更改列名
colnames(table1) <- c("Level","Unmatched",NA,NA,NA,"Level","IPTW",NA,NA,NA)
#打印或导出Excel
print(table1, quote = FALSE)
write.csv(table1, file = "table1.csv")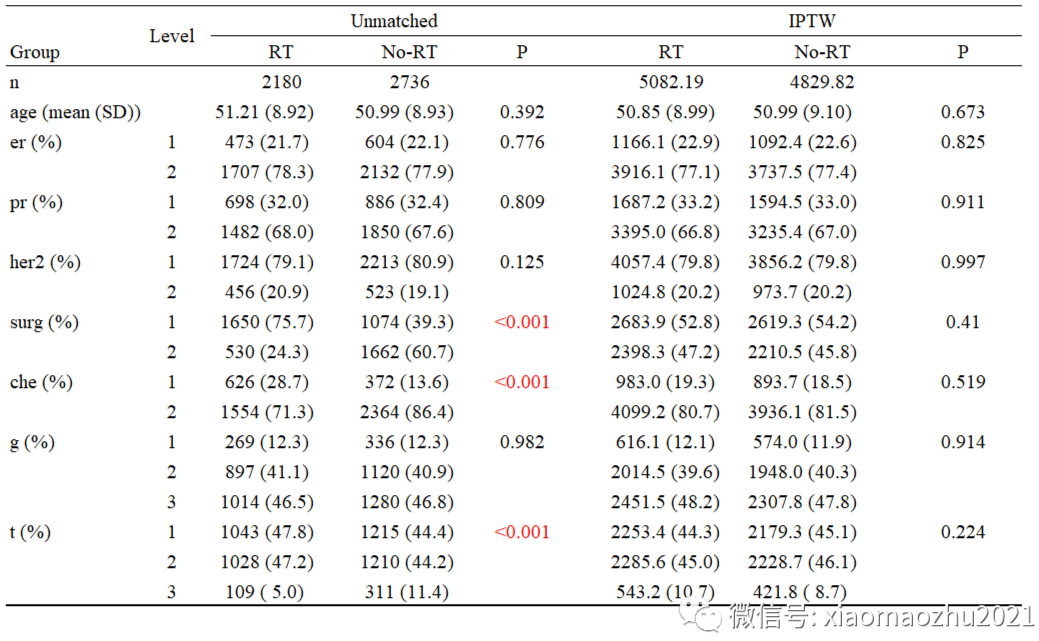
小结
1. 倾向评分是将多个混杂因素综合为一个评分(概率),通过平衡治疗组和对照组的PS而有效地均衡混杂因素的分布,从而达到控制混杂偏倚;
2. PS法本身不能控制混杂,而是通过匹配、分层、加权等方式进行均衡混杂;
3. IPTW加权:患者多个混杂因素计算为1个PS值,将PS和1-PS取倒数作为患者权重,使PS或1-PS小的患者权重变大,进而使多个混杂因素在治疗组和对照组达到均衡而样本量不变。
4. 倾向性评分思路:计算PS+利用PS校正混杂+验证+应用新数据分析。4-1. PS使用方法主要有:
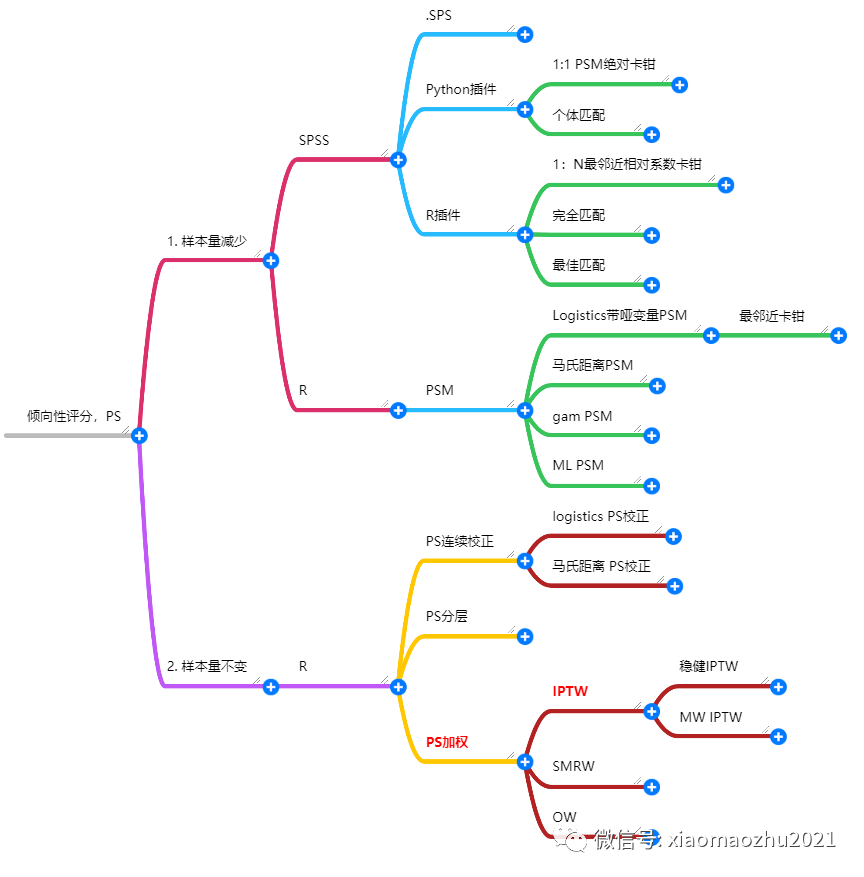
4-2. 应用:基于生存资料,校正KM曲线、校正Cox回归p值和HR值等5. 计算PS的方法,最常用是logistics回归模型,还有probit模型、SVM、分类回归树、boosting算法、神经网络模型等。
特别申明:本文为转载文章,转载自小毛竹 一只勤奋的科研喵,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/bTVwW9yUQ8RZ7QOTeSYD2Q
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫