
交叉验证在机器学习模型中的主要目的是为了防止过拟合,并提高模型的泛化能力。过拟合是指模型在训练数据上训练得过于完善,但在新的未见数据上表现不佳。
什么是“训练-测试-验证”?我们通常根据训练-测试拆分,会将同一个数据集分为训练和测试。训练集用于训练模型。模型参数从训练集中学习它们的值。最终评估是在测试集上进行的,该测试集在训练期间模型是不知道的。除了训练-测试集外,还有另一个被称为验证集的数据集。
一个非常简单的划分方法:我们可以通过两次调用 Scikit-learn 的 train_test_split() 函数,将整个数据集分为训练集、测试集和验证集。
X_train, X_rem, y_train, y_rem = train_test_split(X, y,
train_size=0.70)
X_valid, X_test, y_valid, y_test = train_test_split(X_rem,y_rem,
test_size=0.15)训练集(X_train 和 y_train 部分)占70% ,测试集和验证集(X_test 和 y_test 部分)占 15%
1、训练数据和模型
本文的数据是python自带的iris鸢尾花数据集,模型用随机森林简单展示。代码如下:
from sklearn.model_selection import train_test_split
import pandas as pd
dataset = pd.read_csv('/home/mw/project/iris.csv')
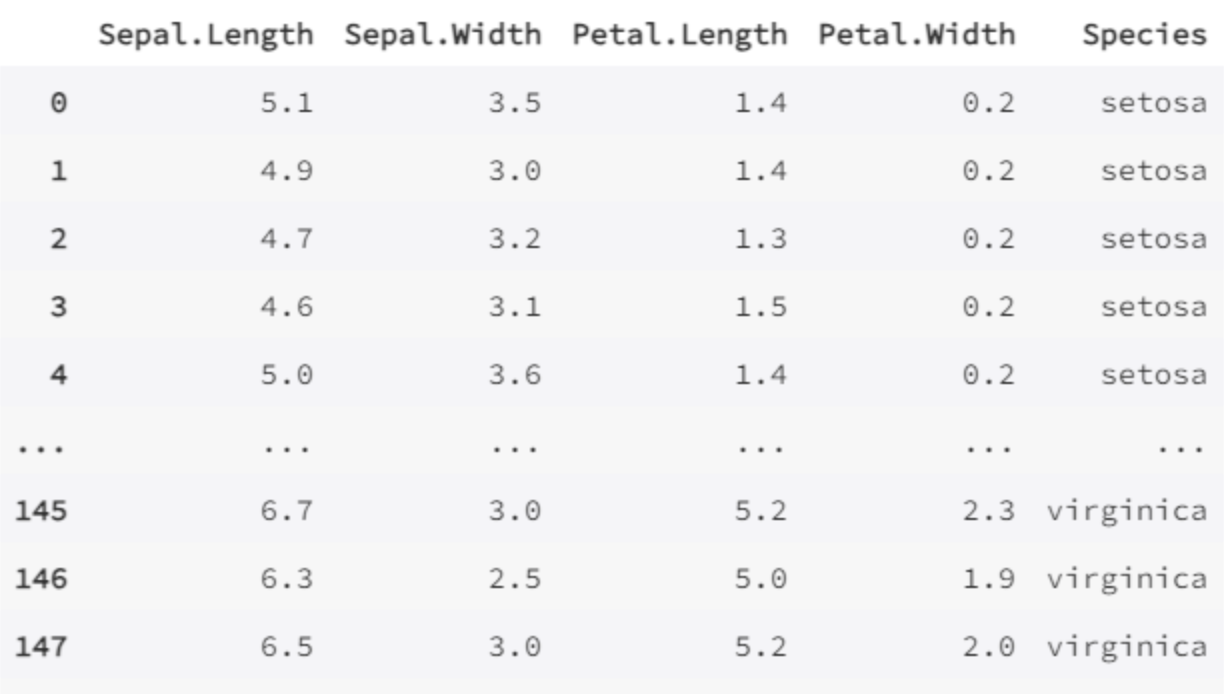
我们用四个花的属性预测类别(即这是一个分类问题):
X = dataset[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']]
y = dataset['Species']2、训练-测试拆分

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.80)
#当数据集较小时,应为训练集分配大约 70-80% 的实例。
#当数据集非常大时,应为训练集分配大约 95-98% 的实例。#训练出我们的随机森林模型:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=0)
model = model.fit(X_train,y_train)
score_c = model.score(X_test, y_test)3k折交叉验证
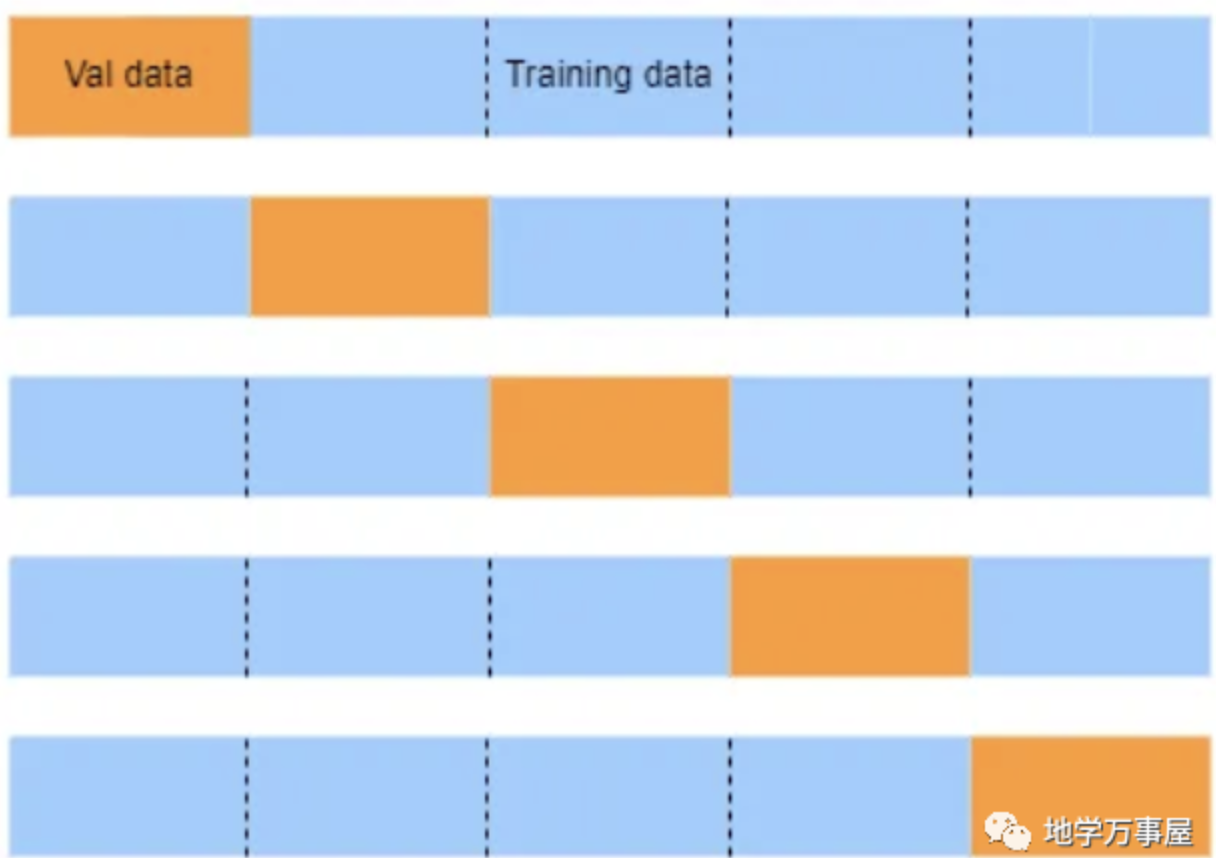
在k折交叉验证中,原始数据集或训练数据集被拆分为k个折叠(子集)。然后,我们训练模型k次(迭代),并获得k个性能估计。在每次迭代中,我们使用一个折叠(验证折叠)评估模型,剩余的k-1个折叠用于训练模型。
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True)
for train_index, val_index in kf.split(X, y):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# 在训练集上训练模型,然后在验证集上进行评估
model.fit(X_train, y_train)
score = model.score(X_val, y_val)
# 打印模型评估结果
print("Validation score:", score)
# X represents the entire dataset我们可以使用 Scikit-learn 的 GridSearchCV() 或 RandomizedSearchCV() 函数进行带有交叉验证的超参数调整。打印gs.best_params_变量
from sklearn.model_selection import GridSearchCV
hyperparameter_space ={'n_estimators':range(1,101,10)}
gs = GridSearchCV(model, param_grid=hyperparameter_space,
scoring="accuracy", cv=5)
gs.fit(X_train, y_train)4、分层k折交叉验证
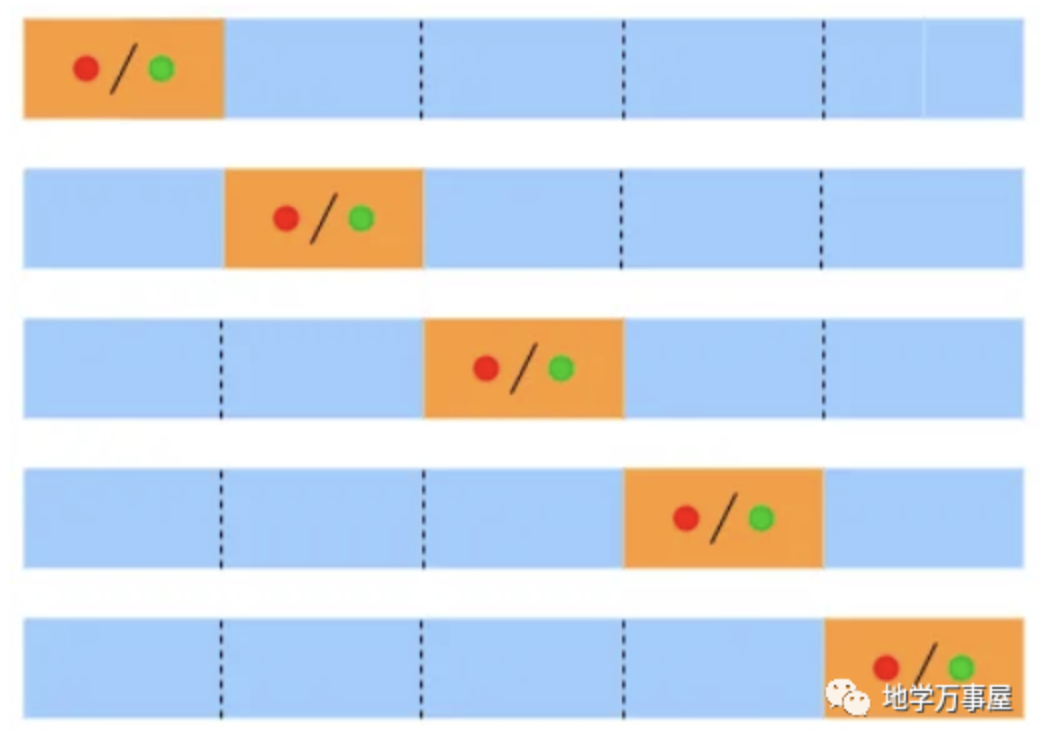
分层K-Fold是K-Fold交叉验证法的一个增强版,主要用于不平衡数据集。就像K-fold一样,整个数据集被分为大小相同的K-fold。不同之处在于,每个Fold保留了整个数据集中类标签实例的百分比。因此,分层k折交叉验证适用于类别不平衡的数据集。我们可以使用 Scikit-learn 的 StratifiedKFold() 函数来执行分层k折交叉验证。折叠数在 n_splits 超参数中指定。
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True)
for train_index, val_index in skf.split(X, y):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# 在训练集上训练模型,然后在验证集上进行评估
model.fit(X_train, y_train)
score = model.score(X_val, y_val)
# 打印模型评估结果
print("Validation score:", score)5、留一交叉验证
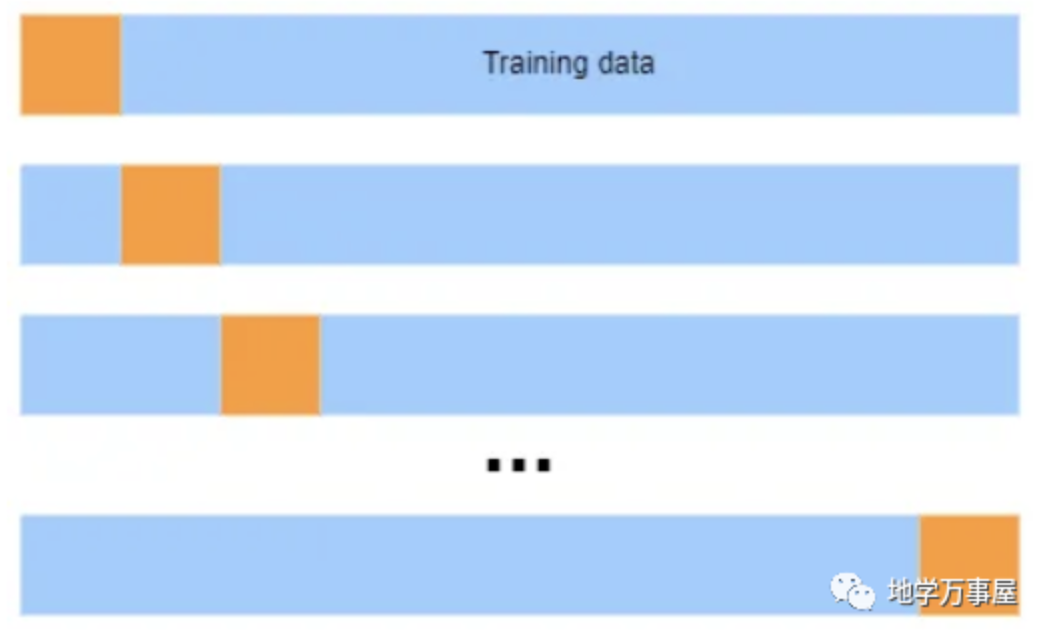
留一交叉验证(LOOCV)是k折交叉验证的一个特殊情况,其中k等于n(数据点的总数)。在LOOCV中,一个数据点被用作验证折叠,其余的n-1个折叠用作训练集。迭代的总次数也等于n。可以使用 Scikit-learn 的 LeaveOneOut() 函数执行留一交叉验证。
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
for train_index, val_index in loo.split(X, y):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# 在训练集上训练模型,然后在验证集上进行评估
model.fit(X_train, y_train)
score = model.score(X_val, y_val)
# 打印模型评估结果
print("Validation score:", score)6、留出交叉验证
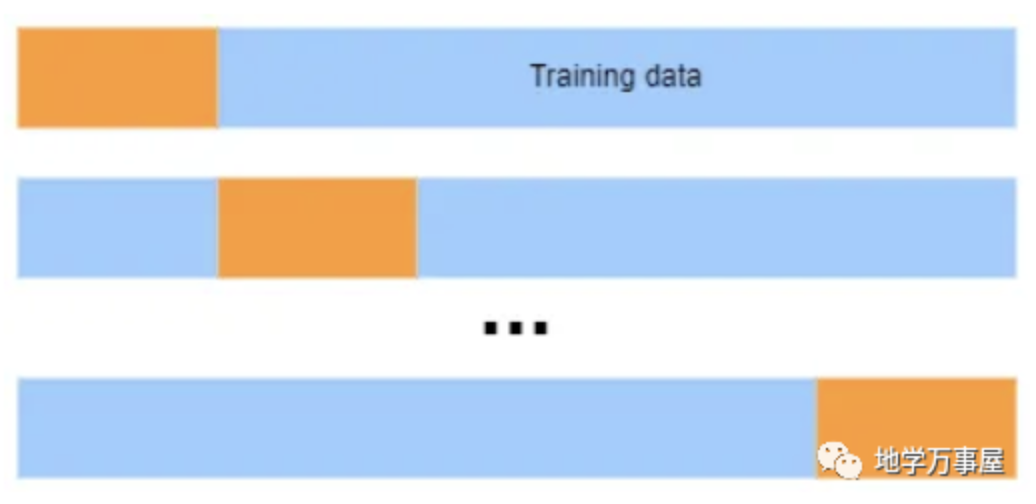
留出交叉验证的工作原理与k折交叉验证完全相同,但每个折叠包含p个数据点,而不是将数据集分成k个折叠。在每次迭代中,p个数据点被用作验证集,其余的n-p个数据点用于训练模型。在k折交叉验证中,如果k=5,则每个折叠有20(100/5)个数据点。在留一出交叉验证中,每个折叠只有一个数据点。在留p出交叉验证中,如果p=5,则每个折叠有5个数据点。可以使用 Scikit-learn 的 LeavePOut() 函数执行留p出交叉验证。
from sklearn.model_selection import LeavePOut
lpo = LeavePOut(5)7、蒙特卡罗交叉验证

蒙特卡洛交叉验证(Monte Carlo CV)将数据集分为训练集和验证集,类似于留出验证,但这个过程会重复多次(迭代)。就像在留出验证中一样,我们需要指定用作训练集或验证集的原始数据集的百分比。
- 拆分迭代的次数也可以作为一个超参数来定义。更多的迭代次数会导致更好的性能,但也增加了计算成本。
- 蒙特卡洛交叉验证的每次迭代中拆分是随机进行的,同一个数据点可以多次出现在测试折叠中。但在k折交叉验证中,这种情况不会发生!
- 在蒙特卡洛交叉验证中,有些数据点永远不会被选为验证折叠!
from sklearn.model_selection import ShuffleSplit
MC = ShuffleSplit(n_splits=10, test_size=0.15)
for train_index, val_index in MC.split(X, y):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# 在训练集上训练模型,然后在验证集上进行评估
model.fit(X_train, y_train)
score = model.score(X_val, y_val)
# 打印模型评估结果
print("Validation score:", score)8、时间序列交叉验证
上述交叉验证方法可能不适合评估时间序列模型,因为在时间序列数据中,数据的顺序非常重要。
在时间序列交叉验证中,折叠以前向链接的方式创建。我们从作为训练折叠的一小部分数据开始,并使用更小的数据子集作为验证折叠。验证折叠随时间向前移动,而前一个验证折叠在下一次迭代中被添加到训练折叠中。我们可以使用 Scikit-learn 的 TimeSeriesSplit() 函数来执行时间序列交叉验证。拆分的次数在 n_splits 超参数中指定。
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
# X represents the entire dataset
for train_index, val_index in tscv.split(X, y):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# 在训练集上训练模型,然后在验证集上进行评估
model.fit(X_train, y_train)
score = model.score(X_val, y_val)
# 打印模型评估结果
print("Validation score:", score)特别申明:本文为转载文章,转载自 地学万事屋,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/eCp1g0vLXSPGzx4MQsC88Q
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


Comments(2)
最近在搞这个?
@8619:随便乱看看