组轨迹模型(Group-Based Trajectory Modeling,GBTM)全称基于群体的轨迹建模,是一种用于分析发展轨迹的统计方法,特别是在研究个体在一段时间内如何随时间变化的情境中。这种方法通常用于心理学、社会学、流行病学和其他领域,以研究个体发展过程中的模式和趋势。
从统计角度来看,Group-Based Trajectory Modeling其实是一种半参数化模型,它允许研究者在保持一定参数化结构的同时,也能够探索和适应数据中的非参数化特征,从而更全面地理解和描述个体发展过程中的复杂性。
轨迹模型的基本思想
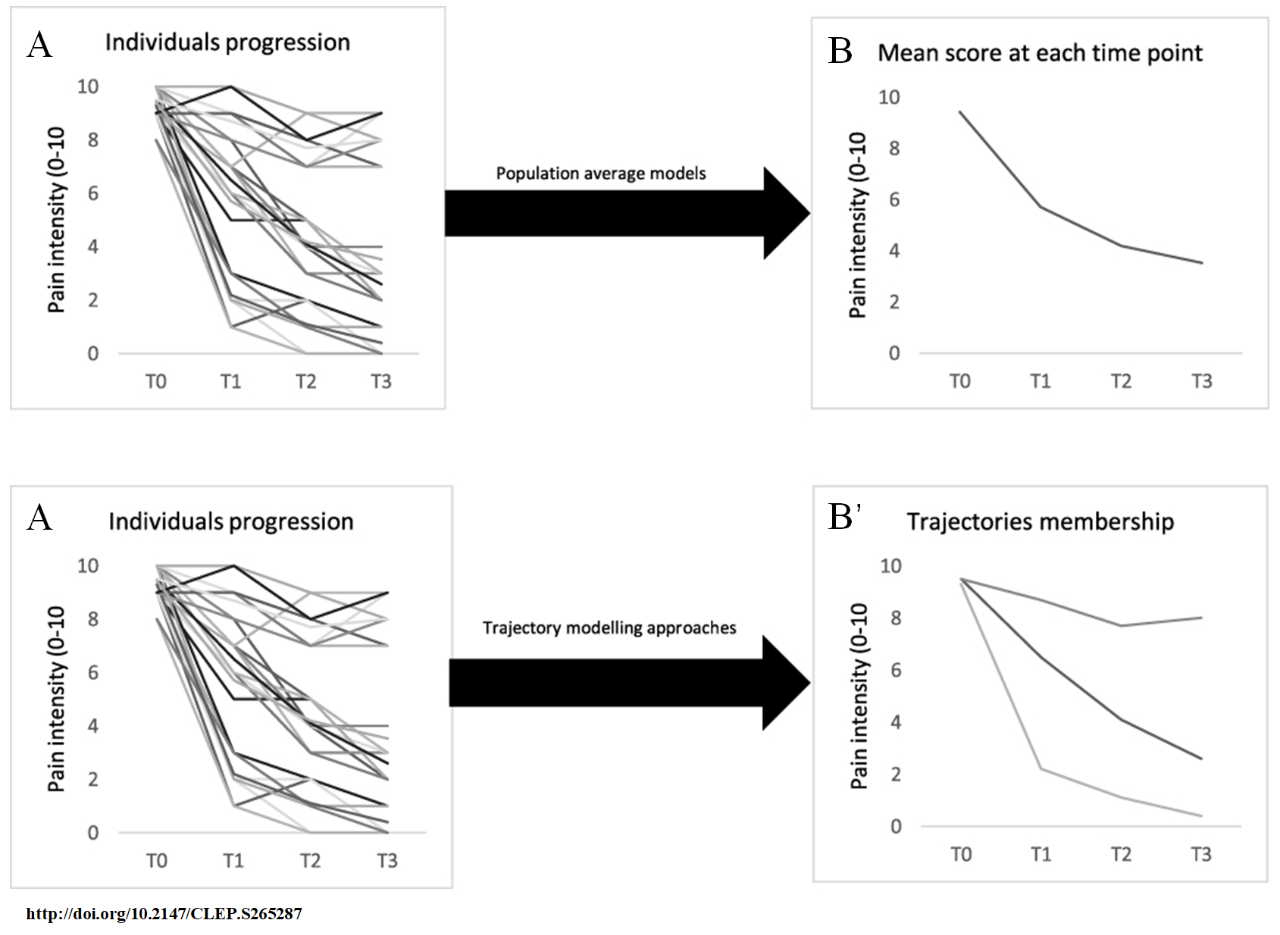
我们通过下图来理解一下轨迹模型的基本思想。假设有一份纵向数据,随访了一批患者4个时间点的疼痛分数 (分数越大,表示越疼痛),4个时间点分别命名为T0、T1、T2、T3。A图展示的是这一批患者4个时间点的疼痛分数变化情况,每一条折线代表了一个患者。
传统的纵向数据分析方法,关注的是这一批患者的疼痛分数在4个时间点的变化平均变化趋势,各时间点不同患者的变异,将会采用方差的大小进行拟合,模型最终拟合的平均趋势将会得到B图的平均变化趋势。
而对于轨迹模型,它假设这一批患者存在两组及以上的亚组,他们的疼痛分数变化趋势在组内是类似的,而组间是有统计学差异的。比如同样对于图A这批数据,轨迹模型就会得到图B’这样三组的平均变化趋势。那么,有多少组才是最符合这批数据的?建模的时候通常会多试几个分组的情况,然后通过AIC、BIC等拟合效果指标进行选择。
R实例
#加载安装包
library("lcmm")
library("NormPsy")
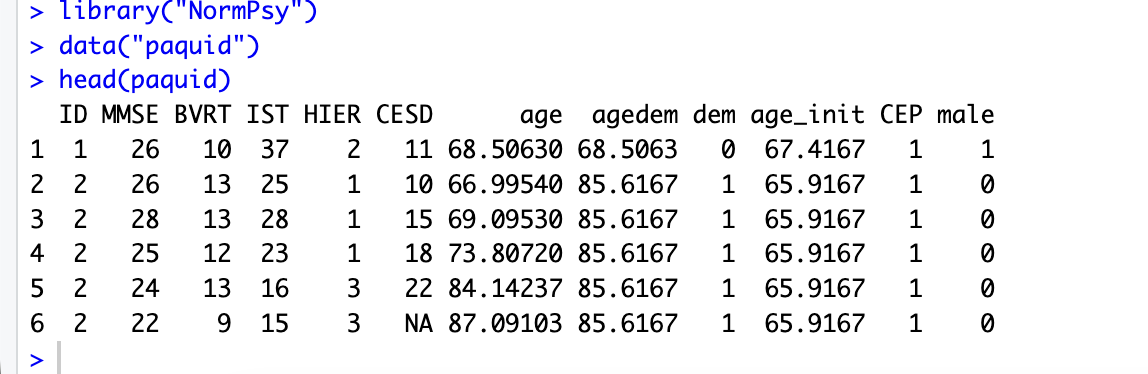
data("paquid")
head(paquid)以上代码分别表示:(1)加载已安装好的软件包。(2)调取软件包自带的数据集paquid,包含2250行,12个变量。(3)预览数据的前6行,如下图。变量包括:ID:患者编号;MMSE、BVRT、IST:是三个表示认知的得分;HIER:表示药物依赖等级;CESD:表示抑郁症状;age:表示年龄;agedem:表示痴呆诊断的年龄;dem:表示是否痴呆;age_init:表示进入队列研究的年龄;CEP:表示是否受教育;male:表示是否为男性。
paquid$normMMSE <- normMMSE(paquid$MMSE)
paquid$age65 <- (paquid$age - 65) / 10以上两行代码是为了后续建模做准备的。分别表示:(1)将MMSE认知得分标化为0到100的标准分。(2)将年龄转化为以65岁为原点,10为单位的年龄变量。
m1 <- hlme(normMMSE ~ poly(age65, degree = 2, raw = TRUE) + CEP,
random = ~ poly(age65, degree = 2, raw = TRUE),
subject = "ID",
data = paquid,
ng = 1)
m2 <- hlme(normMMSE ~ poly(age65, degree = 2, raw = TRUE) + CEP,
random = ~ poly(age65, degree = 2, raw = TRUE),
mixture = ~ poly(age65, degree = 2, raw = TRUE),
subject = "ID",
data = paquid,
ng = 2,
B = m1)
m3 <- hlme(normMMSE ~ poly(age65, degree = 2, raw = TRUE) + CEP,
random = ~ poly(age65, degree = 2, raw = TRUE),
mixture = ~ poly(age65, degree = 2, raw = TRUE),
subject = "ID",
data = paquid,
ng = 3,
B = m1)
m4 <- hlme(normMMSE ~ poly(age65, degree = 2, raw = TRUE) + CEP,
random = ~ poly(age65, degree = 2, raw = TRUE),
mixture = ~ poly(age65, degree = 2, raw = TRUE),
subject = "ID",
data = paquid,
ng = 4,
B = m1)以上代码为构建组别数目为1的轨迹模型,其中poly表示假设认知得分随着年龄的变化轨迹为二次项,CEP为校正的混杂因素。
以上代码为构建组别数目为2的轨迹模型,当设定的组数大于1时,需要给定初始值B,一般设定组数为1时的参数。此外相比于模型m1还多了一个mixture的设置,表示各组的平均轨迹随年龄变化的趋势。
同上,分别构建组别数目为3和4的轨迹模型。
summarytable(m1, m2, m3, m4)
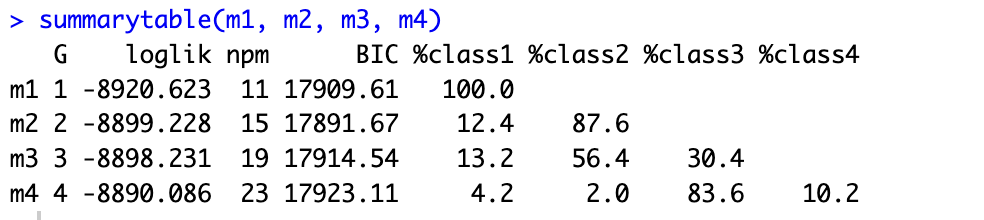
以上代码用于比较四个模型的拟合效果,结果如下,根据BIC最小的原则,m2最优。
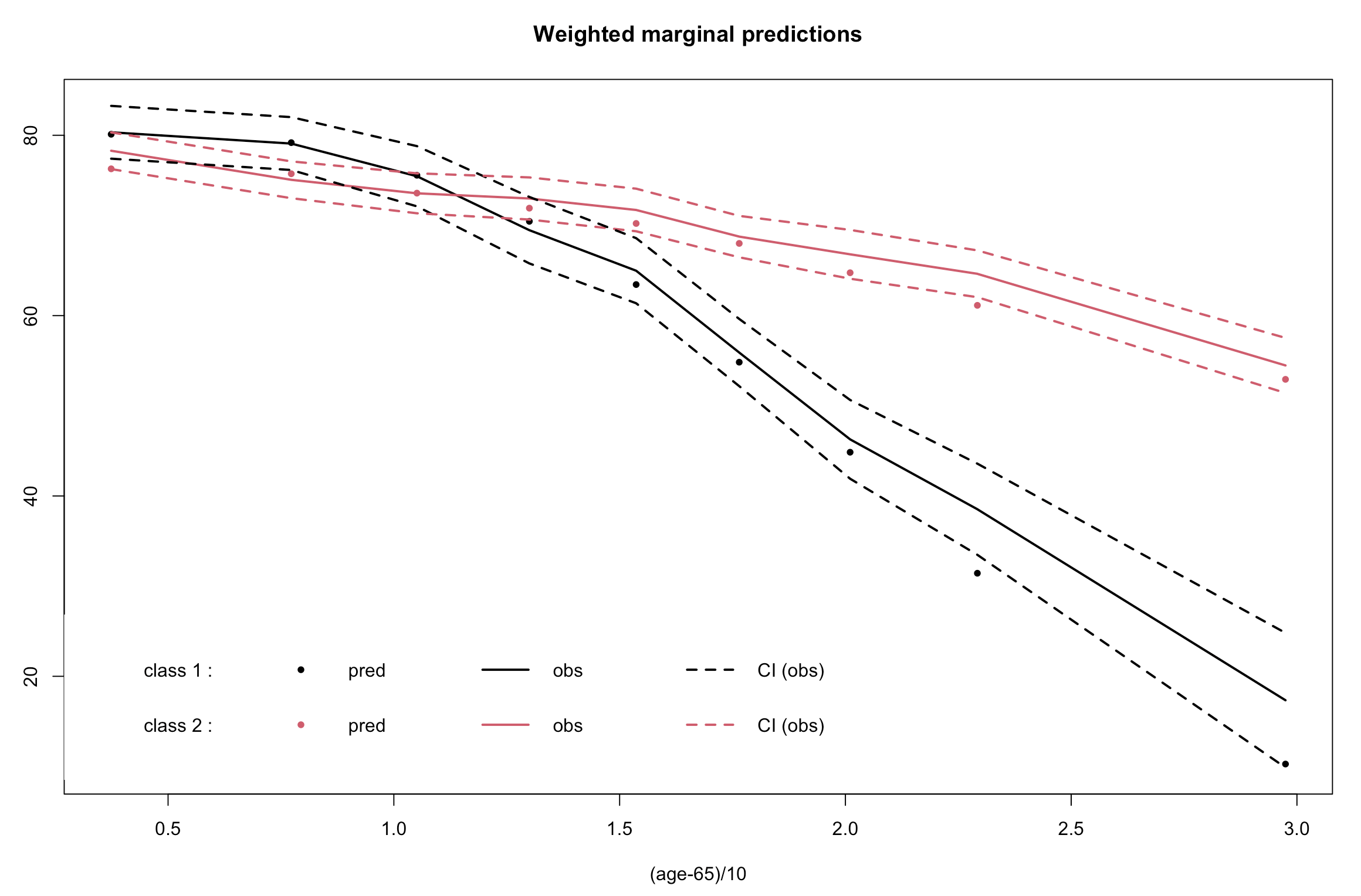
plot(m2,
which = "fit",
var.time = "age65",
ylab = "normMMSE",
xlab = "(age-65)/10",
lwd = 2)以上代码为查看两组的轨迹,轨迹如下图。可以看到两组区分比较明显的,组1 (class1) 是快速下降组,组2 (class2) 是缓慢下降组。
head(m2$pprob)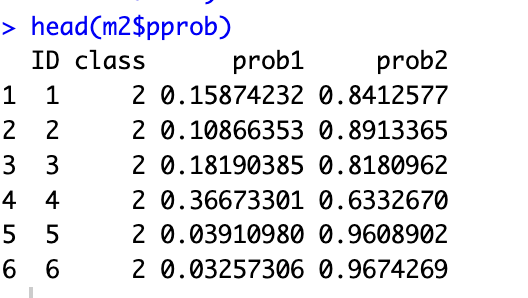
轨迹模型主要的功能在于分组,所以获得数据中每位研究对象的分组信息非常重要,而这个信息储存在m2模型的pprob元素中,以上代码为预览分组结果,结果如图。ID为研究对象的唯一编号,class为分组的结果。
特别申明:本文为转载文章,转载自统计咨询,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/9xjFd0ftdljQYgucr6otPQ
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫