
基于KM曲线
使用KM曲线取连续变量的最佳cutoff值。其基本原理是基于log-rank检验,使某点两侧的数据有最佳的差异性。此法转换的分类变量的单因素cox回归分析往往都有意义。其缺点也很明显,基于自己数据,cutoff值可能与临床常用的有差异。
#载入R包和数据
library(survival)
library(survminer)
#清理运行环境
rm(list = ls())
#数据来自survminer包自带数据集:myeloma。
#读入该数据集
data(myeloma)
#查看该数据变量及性质
str(myeloma)
#该数据集是一个多发性骨髓瘤的基因表达数据(GEO ID:GSE4581)。
?myeloma#该命令可以查看R语言自带数据集的变量意义
# molecular_group:患者的分子亚组
# chr1q21_status:染色体1q21的扩增状态
# treatment:治疗
# event:生存状态0 =存活,1 =死亡
# time:生存时间(以月为单位)
# CCND1:基因表达水平
# CRIM1:基因表达水平
# DEPDC1:基因表达水平
# IRF4:基因表达水平
# TP53:基因表达水平
# WHSC1:基因表达水平
#确定基因表达量的最佳cutoff值
cutoff<-surv_cutpoint(myeloma, #数据集
time="time",#“ ”里写数据集时间变量
event="event",##“ ”里数据集结局变量名称
variables=c("DEPDC1","WHSC1", #6个基因表达量
"CRIM1","IRF4",
"TP53","WHSC1")
);summary(cutoff) #输出结果
#可视化某基因表达水平的cutoff值
plot(cutoff,
"DEPDC1",
palette = "lancet") #使用柳叶刀配色
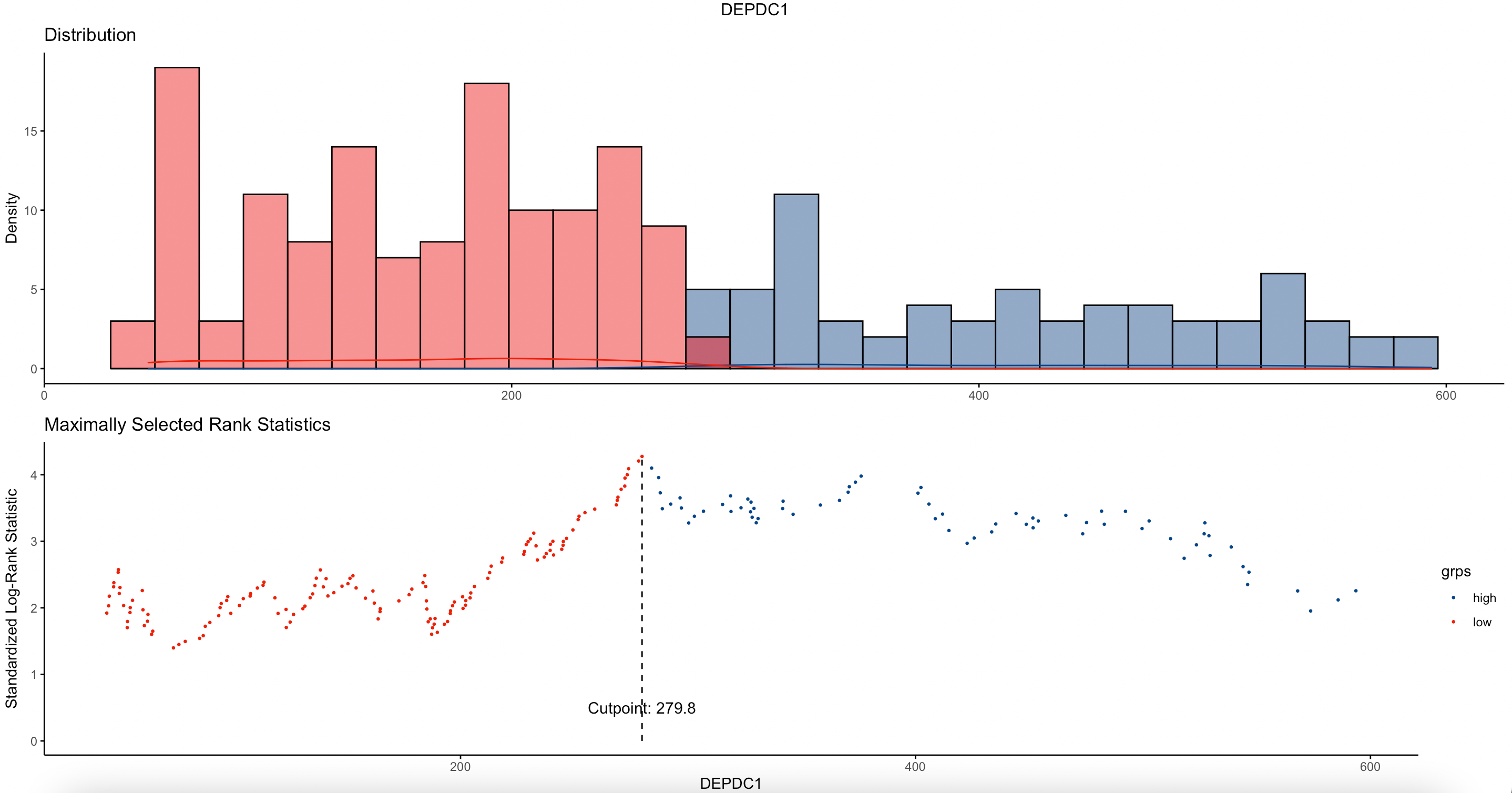
#将连续变量按照上述截断值分组
groups<-surv_categorize(cutoff)
str(groups)
head(groups)
# 绘制KM曲线 注意,要用转为分类变量的数据,data=groups
fit <- survfit(Surv(time, event)~DEPDC1, data=groups)#生存分析函数
ggsurvplot(fit,
data = groups, #使用转为分类的数据集
pval=TRUE, #显示p值
pval.method=TRUE, #显示p值的评估方法
palette = "lancet",#使用柳叶刀配色
risk.table = TRUE, #显示风险表
conf.int = TRUE) #显示CI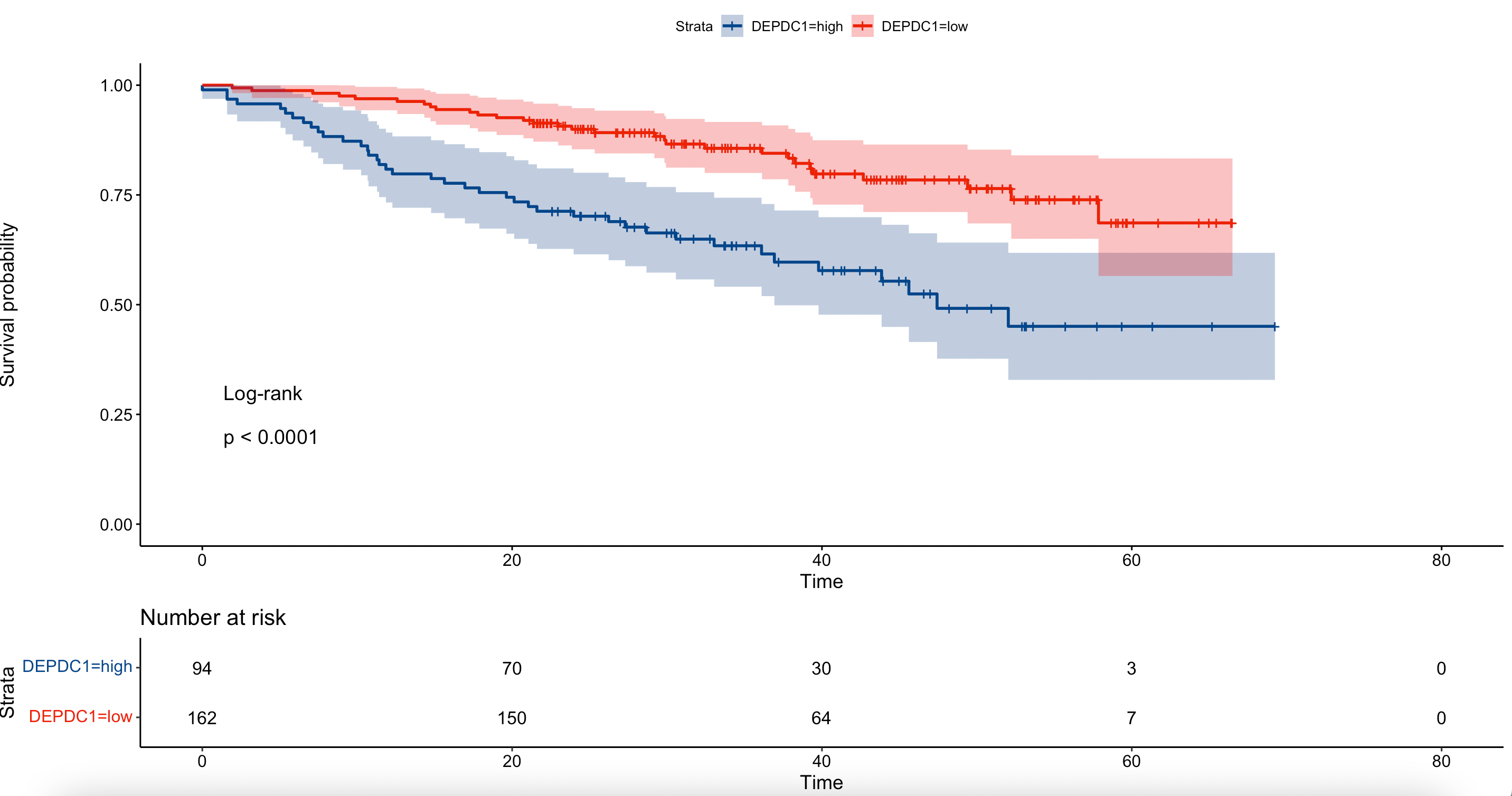
# 单因素Cox回归结果
cutoff_cox<-coxph(Surv(time,event)~DEPDC1,
data=groups);summary(cutoff_cox)
基于surv_cutpoint( )函数,我们可以相对准确的找到某连续变量的最佳cutoff值。因为是基于log-rank检验得出的结果,因此划分出的两个分组一般会具有统计学意义,值得一试。
基于ROC曲线
使用survivalROC包寻找生存资料中连续变量的cutoff值,使用pROC包寻找二分类结局中连续变量的cutoff值。其基本原理是基于约登指数最大的点。
#载入R包和数据
library(survivalROC)
library(survminer)
library(survminer)
#清理运行环境
rm(list = ls())
#数据来自survminer包自带数据集:myeloma。
#读入该数据集
data(myeloma)
#查看该数据变量及性质
str(myeloma)
#该数据集是一个多发性骨髓瘤的基因表达数据(GEO ID:GSE4581)。
?myeloma#该命令可以查看R语言自带数据集的变量意义
# molecular_group:患者的分子亚组
# chr1q21_status:染色体1q21的扩增状态
# treatment:治疗
# event:生存状态0 =存活,1 =死亡
# time:生存时间(以月为单位)
# CCND1:基因表达水平
# CRIM1:基因表达水平
# DEPDC1:基因表达水平
# IRF4:基因表达水平
# TP53:基因表达水平
# WHSC1:基因表达水平
#确定DEPDC1的最佳cutoff值,构建生存ROC函数(survivalROC)
ROC<-survivalROC(Stime=myeloma$time, #生存时间=time
status=myeloma$event, #生存状态=event
marker=myeloma$DEPDC1,#需要分析的变量
predict.time=36, #预测时间,36月
method="KM") #使用生存分析KM计算
#约登指数最大对应的值为最佳cutoff
cutoff<-ROC$cut.values[which.max(ROC$TP-ROC$FP)];cutoff其结果是:279.8。
# 可视化ROC结果
plot(ROC$FP, #x轴
ROC$TP, #y轴
type="l",#线型为线条
xlim=c(0,1),
ylim=c(0,1),
xlab=paste("FP","\n","AUC=",round(ROC$AUC,3)),#x轴名字、添加AUC值
ylab="TP", #y轴名字
main="3-year survival ROC",col="red")+
abline(0,1)+#斜线
legend("bottomright",c("DEPDC1"),col="red",lty=c(1,1))#标签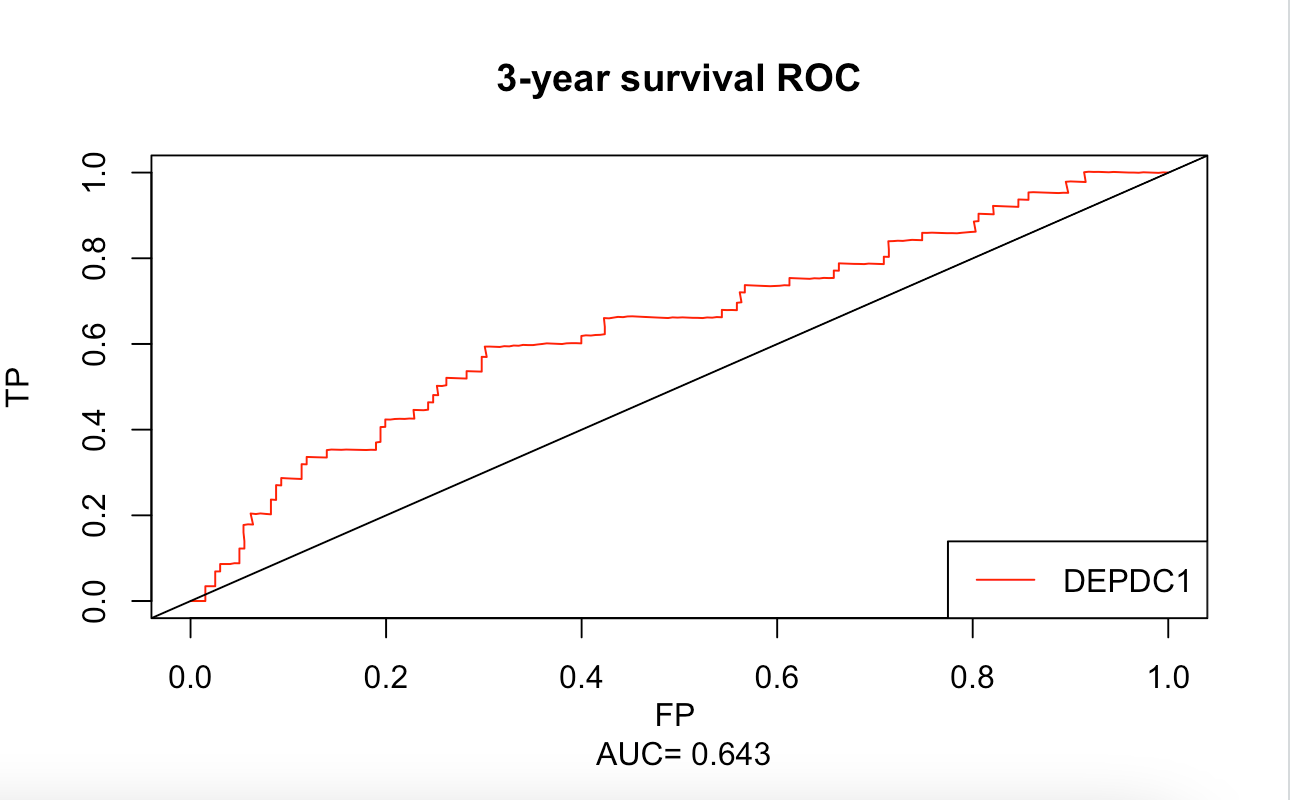
# KM曲线和单因素Cox回归验证
# 将变量按上述cutoff值分类
# 解释ifelse( )函数:假如DEPDC1变量中有大于279.8的数值,定义为high,否则为low ,这样就将该列连续变量(DEPDC1)转为分类变量(new_DEPDC11)了。
myeloma$new_DEPDC11<-ifelse(myeloma$DEPDC1>279.8,"high","low")
#KM曲线验证分类变量
fit <- survfit(Surv(time, event)~new_DEPDC11, data=myeloma)
ggsurvplot(fit,
data=myeloma,
pval=TRUE,
pval.method=TRUE,
palette = "lancet",
risk.table = TRUE,
conf.int = TRUE)
# 单因素Cox回归验证
cutoff_cox<-coxph(Surv(time,event)~new_DEPDC11,
data=myeloma);summary(cutoff_cox)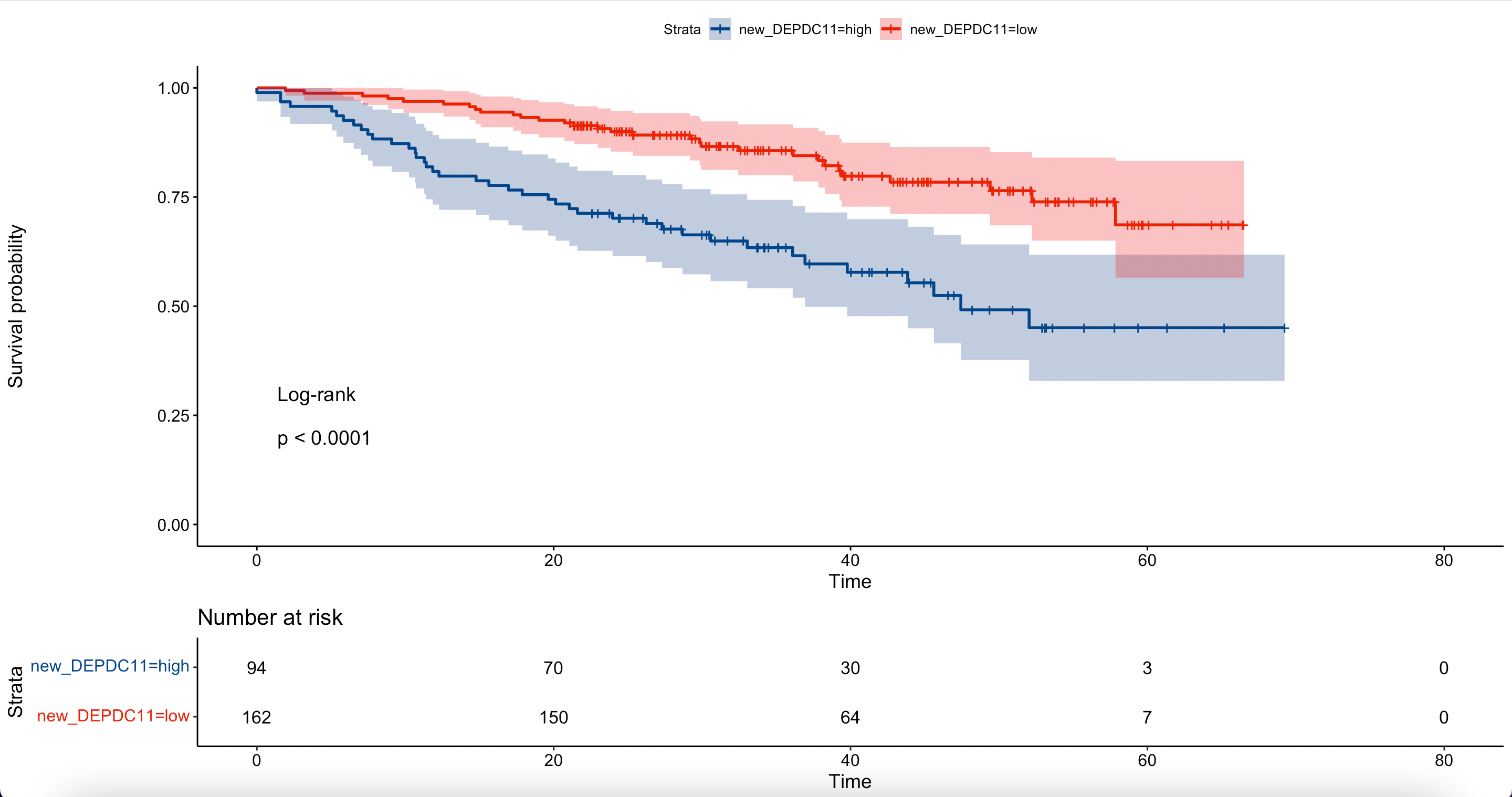
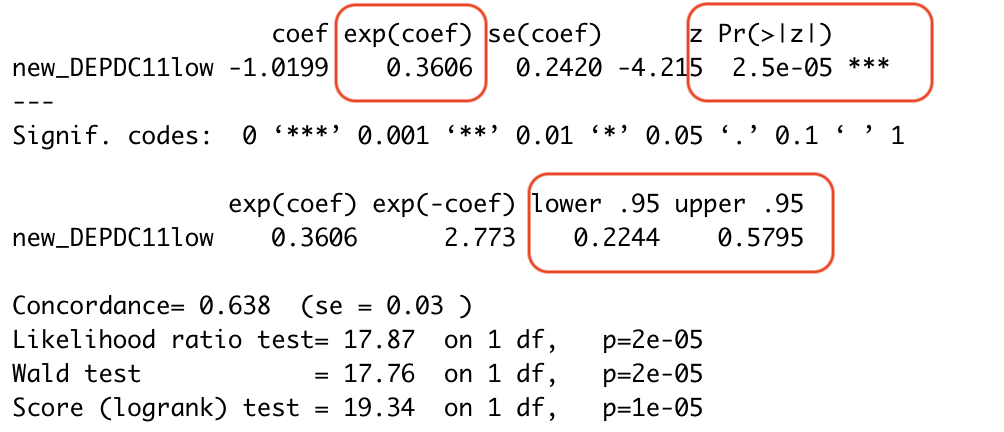
我们使用KM法和survivalROC包取得的连续变量DEPDC1的cutoff值是一致的,均为279.8。因此其KM曲线和单因素Cox回归结果也一致。
特别申明:本文为转载文章,转载自小毛竹 一只勤奋的科研喵,不代表贪吃的夜猫子立场,如若转载,请注明出处:https://mp.weixin.qq.com/s/5vYxN3Cz4AOhF7-3jqRk7w
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


Comments(1)
summary(cutoff) #输出结果后面提示
Warning messages:
In min(which(Test == STATISTIC)) :
no non-missing arguments to min; returning Inf
怎么解决,求答(DFS均已达到,event都是0,跟这个有关吗)