Lasso回归是线性回归的拓展,其实就是在线性回归中加入L1正则化项,实现对模型参数的惩罚,使得一部分参数趋近于零,简单来说就是其可以在模型中删除不必要的特征或参数,使模型更简单,从而避免过拟合。
在临床预测中,可能存在大量的生物医学特征,其中一些可能不是很重要。
- Lasso可以自动将某些特征的系数估计为零,从而实现特征选择,帮助减少模型中的不必要的特征,这样生成的模型更容易解释,只包含最重要的特征,更便于医生或临床决策者理解模型的预测结果。
- 而且Lasso在样本数量相对较少的情况下也可以很好地工作,尤其是在高维数据中,它有助于防止过拟合,即使数据点有限。
- 另外,Lasso回归可以通过自变量之间的相关关系,将相关的自变量的系数变为0,从而降低多重共线性对回归结果的影响。
注:L2正则化是岭回归。原理是将曲线过于陡峭的某些部分变得平缓,从而控制模型的复杂程度。简单来说就是Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但和Lasso回归比,这会使得模型的特征留的特别多,模型解释性差。
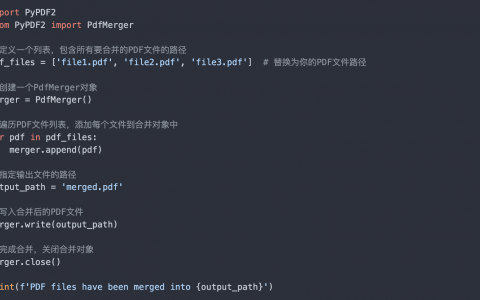
R包安装
install.packages("glmnet")
library(glmnet)- glmnet包可以实现Lasso回归、岭回归、弹性网络(elastic-net),它适合线性、logistic和多项式、泊松等回归模型。它还可以拟合多元线性回归模型、定制族广义线性回归模型和lasso回归模型,在该软件包中还拥有预测、绘图、交叉验证的方法。
- 在glmnet包中,lambda是总的正则化程度,该值越大,惩罚力度就越大,最终保留的变量越少,模型的复杂程度越低;alpha是L1正则化比例,当alpha=1时,是Lasso回归(L1正则化),当alpha=0时,是岭回归(L2正则化),0<alpha<1时,是弹性网络,弹性网络是L1和L2正则化的结合,可以平衡两者的影响。
回归模型
data("BinomialExample")
x<-BinomialExample$x
y<-BinomialExample$y
fit <- glmnet(x, y, family = "binomial",alpha=1)#alpha默认值是1
#'cox'生存分析,'gaussian':连续性数值因变量OLS回归,
#'binomial':二元分类,Logistic回归,'poisson':因变量是计数数据,泊松分布
#'multinomial':多类别分类问题,
#'mgaussian':用于多元高斯分布,假设因变量是多维连续数值型数据,且服从多元高斯分布。这可以用于多元回归问题
打印
print(fit)
#参数解释
#Df:非零系数的个数
#%Dev:模型解释度
#Lambda:正则化参数
绘图
plot(fit,
xvar='lambda',#'norm'是默认值,为L1 Norm;'lambda':log-lambda;'dev':模型解释的%deviance
label=T)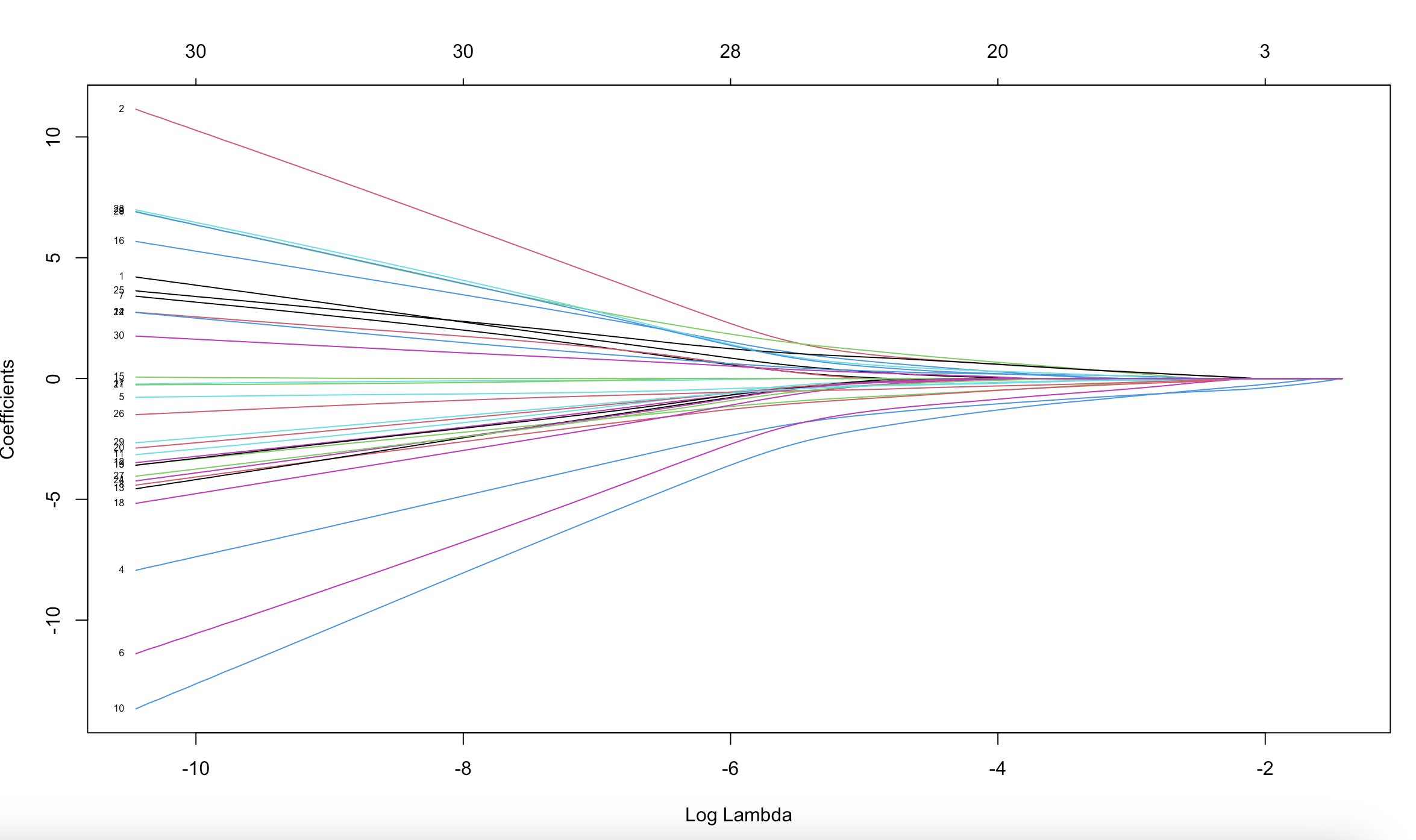
回归系数路径图,图中的每一条线都代表着一个变量,每条线末尾的数字是变量编号,纵坐标为系数,上横坐标是不同正则化参数下模型中非零系数的个数。下横坐标是标准化后的正则化参数。该图展示了在不同的正则化参数下变量系数的变化轨迹。
当正则化越大时,模型的复杂程度越低,因此大部分参数会趋近于0,我们可以通过该图了解到哪些特征对模型的预测贡献较大或较小,可以初步将贡献较大的特征用作后续的分析,例如特征2和10。
交叉验证
Lasso回归交叉验证曲线是一种用于选择最优正则化参数的可视化工具。set.seed(123)
cvfit<-cv.glmnet(x,y, family = "binomial",alpha=1,type.measure = 'deviance')
print(cvfit)
# Call: cv.glmnet(x = x, y = y, type.measure = "deviance", family = "binomial", alpha = 1)
#
# Measure: Binomial Deviance
#
# Lambda Index Measure SE Nonzero
# min 0.02141 27 0.8091 0.08923 19
# 1se 0.04945 18 0.8944 0.06460 13
plot(cvfit)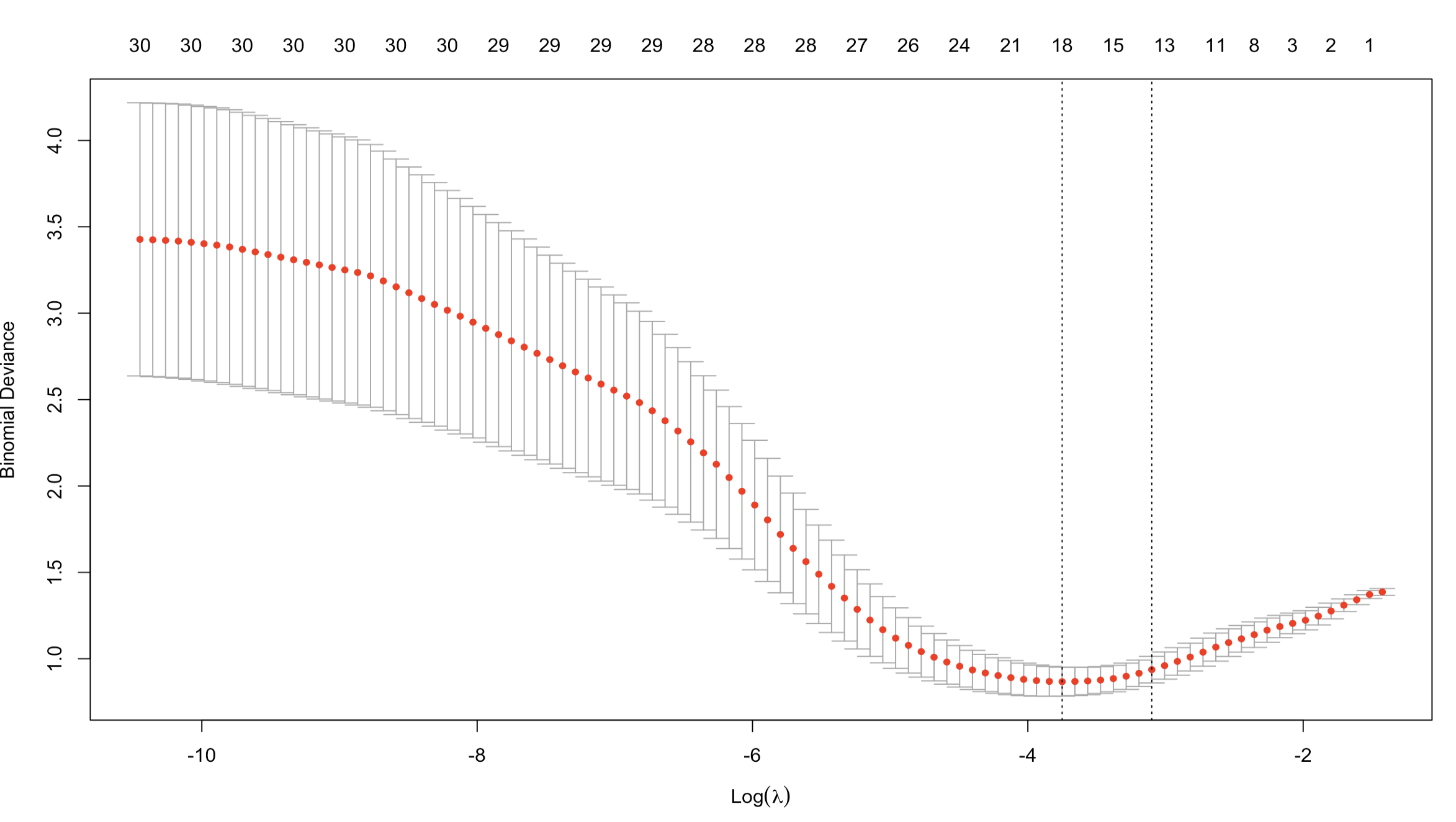
Lasso回归交叉验证曲线是一种用于选择最优正则化参数的可视化工具。
- 该图下x轴为标准化后的正则化参数,上x轴为不同正则化参数下模型非零系数的个数,y轴为似然偏差,一周越说说明模型的拟合效果越好。
- 左侧的虚线对应曲线的最低点,为lambda.min,给出最小的平均交叉验证误差。右侧的虚线为lambda.lse,它使得交叉验证的误差在最小的一个标准方差范围内,该值对应的模型拟合效果好,选择的特征少,因此模型会更简单,因此临床上一般选择lambda.lse作为最终方差筛选标准,从图上看lambda.lse对应的特征数为在13左右。
获得lambda值和查看全部特征的系数
cvfit$lambda.min
#[1] 0.02140756
cvfit$lambda.1se
#[1] 0.04945423
coef<-coef(cvfit, s = "lambda.1se")
# 31 x 1 sparse Matrix of class "dgCMatrix"
# s1
# (Intercept) 0.20679470
# V1 .
# V2 0.27873628
# V3 -0.16579666
# V4 -0.69275750
# V5 -0.07549238
# V6 -0.42352625
# ...coef<-coef@Dimnames[[1]][which(!coef==0)]
coef[-1]
#[1] "V2" "V3" "V4" "V5" "V6" "V8" "V9" "V10" "V22" "V23" "V25" "V26" "V29"
length(coef[-1])
#[1] 13原创文章(本站视频密码:66668888),作者:xujunzju,如若转载,请注明出处:https://zyicu.cn/?p=18576
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫