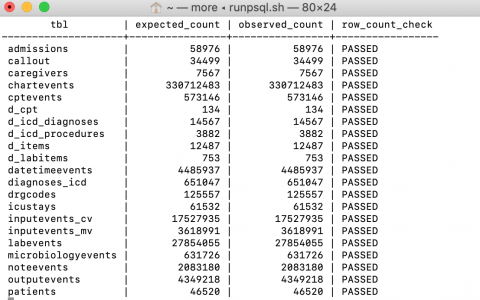
sql查询保存为sql文件,然后通过python查询导出为csv文件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import psycopg2 as pg
conn=pg.connect(database="mimiciv",user="postgres",password="",host="localhost",port="5432")
sql_path = '/Users/xujun/Downloads/'
sql_file = '1.sql'
sql = open(sql_path + sql_file, 'r', encoding='utf8')
sqltxt = sql.readlines()
sql.close()
sql = "".join(sqltxt)
df=pd.read_sql(sql,conn)
df.to_csv('/Users/xujun/Downloads/1.csv')
print('succeed')
conn.close()亲测可行
但是假如文件夹内有很多sql文件,想要批量运行,则可如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import psycopg2 as pg
conn=pg.connect(database="mimiciv",user="postgres",password="",host="localhost",port="5432")
sql_path = '/Users/xujun/Downloads/'
list_1 =['test_1', 'test_2']
for i in list_1:
sql_file = f'{i}'+'.sql'
sql = open(sql_path + sql_file, 'r', encoding='utf8')
sqltxt = sql.readlines()
sql.close()
sql = "".join(sqltxt)
df=pd.read_sql(sql,conn)
df.to_csv(f'{i}'+'.csv')
print('succeed')
conn.close()
假如单独查询某句话:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import psycopg2 as pg
conn=pg.connect(database="mimiciv",user="postgres",password="",host="localhost",port="5432")
sql = 'select * from mimic_icu.d_items limit 15'
df1 = pd.read_sql(sql,conn)
pd.options.display.max_columns = 999
print(df1)
print('succeed')
conn.close()
原创文章(本站视频密码:66668888),作者:xujunzju,如若转载,请注明出处:https://zyicu.cn/?p=7124
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫